



As the scale and complexity of synthetic intelligence fashions proceed to develop, it turns into more and more troublesome to disregard one of many main challenges: reminiscence limitations. Although GPUs have gotten sooner and extra highly effective, large-scale AI methods typically run into what researchers name the “reminiscence wall,” a bottleneck the place an absence of reminiscence capability dramatically reduces computational effectivity.
Now, Korean researchers have developed a promising resolution.
The Electronics and Telecommunications Analysis Institute (ETRI) introduced OmniXtend, an Ethernet-based reminiscence growth know-how. This breakthrough goals to beat reminiscence shortage in large-scale AI coaching environments and has the potential to considerably enhance the scalability, value effectivity, and efficiency of future AI infrastructures.
The speedy rise of large-scale language fashions (LLMs), generative AI, and high-performance computing workloads has dramatically elevated reminiscence calls for. Conventional server architectures tightly couple reminiscence to particular person gadgets, creating vital scalability limitations.
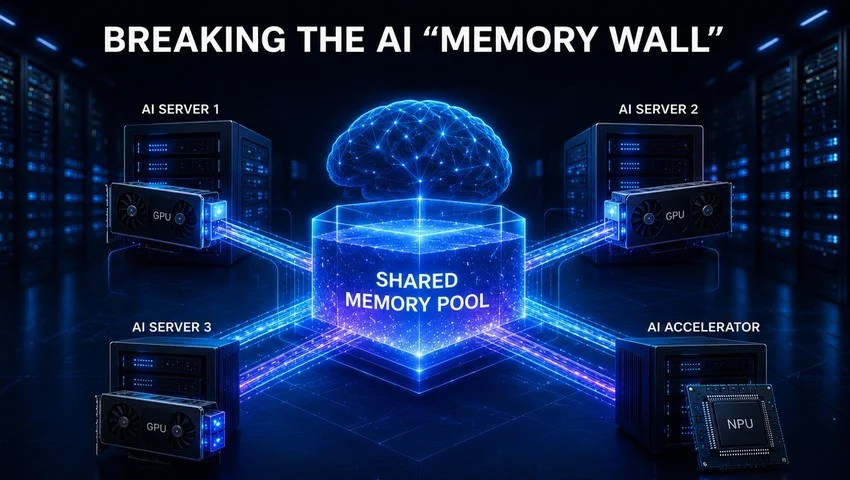
OmniXtend introduces a essentially totally different strategy. Moderately than relying solely on regionally connected reminiscence, it makes use of a normal Ethernet community because the reminiscence interconnect material. This enables reminiscence assets to be pooled and shared dynamically throughout servers and accelerators, creating a big, unified “reminiscence pool” that may be accessed in actual time.
In impact, it permits reminiscence assets distributed all through the community to perform as one coherent, scalable system.
Conventional high-performance computing methods sometimes depend on high-speed serial interfaces similar to PCIe. Though these architectures are efficient for small setups, they’ve limitations in scalability, connectivity distance, and deployment flexibility.
In distinction, OmniXtend leverages present Ethernet infrastructure and customary Ethernet switches to combination a number of bodily distributed gadgets right into a shared reminiscence atmosphere.
The principle advantages are:
Scale back information motion delays throughout AI coaching Develop reminiscence capability with out changing present servers Scale back information heart deployment and working prices Enhance scalability of hyperscale AI methods
This know-how helps AI workloads keep increased efficiency ranges even beneath demanding situations by minimizing memory-related bottlenecks.
To validate the structure, ETRI developed a number of core enabling applied sciences:
Discipline-Programmable Gate Array (FPGA)-based reminiscence growth node Ethernet-based reminiscence switch engine Scalable shared reminiscence administration system
The workforce efficiently demonstrated that a number of gadgets can function in an Ethernet atmosphere whereas accessing shared reminiscence assets in actual time.
In exams utilizing massive language mannequin workloads, researchers noticed that LLM inference efficiency degrades considerably when reminiscence is inadequate. Nonetheless, enabling Ethernet-based reminiscence growth greater than doubled the efficiency. Based on ETRI, this exhibits that shared reminiscence architectures can keep processing efficiency similar to methods with adequate native reminiscence.
ETRI plans to commercialize OmniXtend by partnerships with information heart {hardware} and software program firms. Potential functions embrace AI coaching and inference servers, reminiscence growth gadgets, and high-performance community switches. The institute plans to increase this know-how to high-reliability embedded methods, similar to automotive platforms and marine functions.


