



Offering massive language fashions (LLMs) at scale is a significant engineering problem as a result of key-value (KV) cache administration. As mannequin measurement and inference capabilities develop, the KV cache footprint will increase and turns into a significant throughput and latency bottleneck. For contemporary Transformers, this cache can occupy a number of gigabytes.
NVIDIA researchers launched KVTC (KV Cache Rework Coding). This light-weight remodel coder compresses KV caches for compact on-GPU and off-GPU storage. Obtain as much as 20x compression whereas sustaining accuracy for inference and lengthy contexts. In sure use circumstances, it could attain 40x or extra.
Reminiscence dilemma in LLM reasoning
In manufacturing, the inference framework treats the native KV cache like a database. Methods similar to prefix sharing promote cache reuse and velocity up response. Nevertheless, older caches devour scarce GPU reminiscence. Builders at the moment face troublesome selections.
Protect cache: Occupy reminiscence wanted by different customers. Discard the cache: Recalculation prices are excessive. Cache offload: Strikes information to CPU DRAM or SSD, incurring switch overhead.
KVTC considerably alleviates this dilemma by decreasing on-chip retention prices and decreasing the bandwidth required for offloading.

How does the KVTC pipeline work?
This technique takes inspiration from basic media compression. Apply the discovered orthonormal remodel, adopted by adaptive quantization and entropy coding.
1. Characteristic Correlation (PCA)
Totally different objects of consideration typically present related patterns and excessive correlations. KVTC makes use of principal part evaluation (PCA) to linearly decorrelate options. In contrast to different strategies that compute separate decompositions for every immediate, KVTC computes the PCA foundation matrix V as soon as for the calibration dataset. This matrix is reused for all future caches throughout inference.
2. Adaptive quantization
The system makes use of a PCA order to allocate a hard and fast bit price range throughout coordinates. Excessive variance elements obtain extra bits, whereas different elements obtain fewer bits. KVTC makes use of a dynamic programming (DP) algorithm to search out the optimum bit allocation that minimizes reconfiguration errors. Importantly, DP typically assigns 0 bits to subsequent principal elements, permitting for early dimensionality discount and quick efficiency.
3. Entropy coding
The quantized symbols are packed and compressed utilizing the DEFLATE algorithm. To keep up velocity, KVTC leverages the nvCOMP library to allow parallel compression and decompression immediately on the GPU.
Safety of important tokens
Not all tokens are compressed equally. KVTC avoids compression of two particular varieties of tokens: It’s because these tokens contribute disproportionately to attentional accuracy.
Consideration sink: the 4 oldest tokens within the sequence. Sliding window: Newest 128 tokens.
Ablation research have proven that compressing these explicit tokens can considerably scale back accuracy and even collapse at excessive compression charges.
Benchmarking and effectivity
The analysis group examined KVTC on fashions similar to Llama-3.1, Mistral-NeMo, and R1-Qwen-2.5.
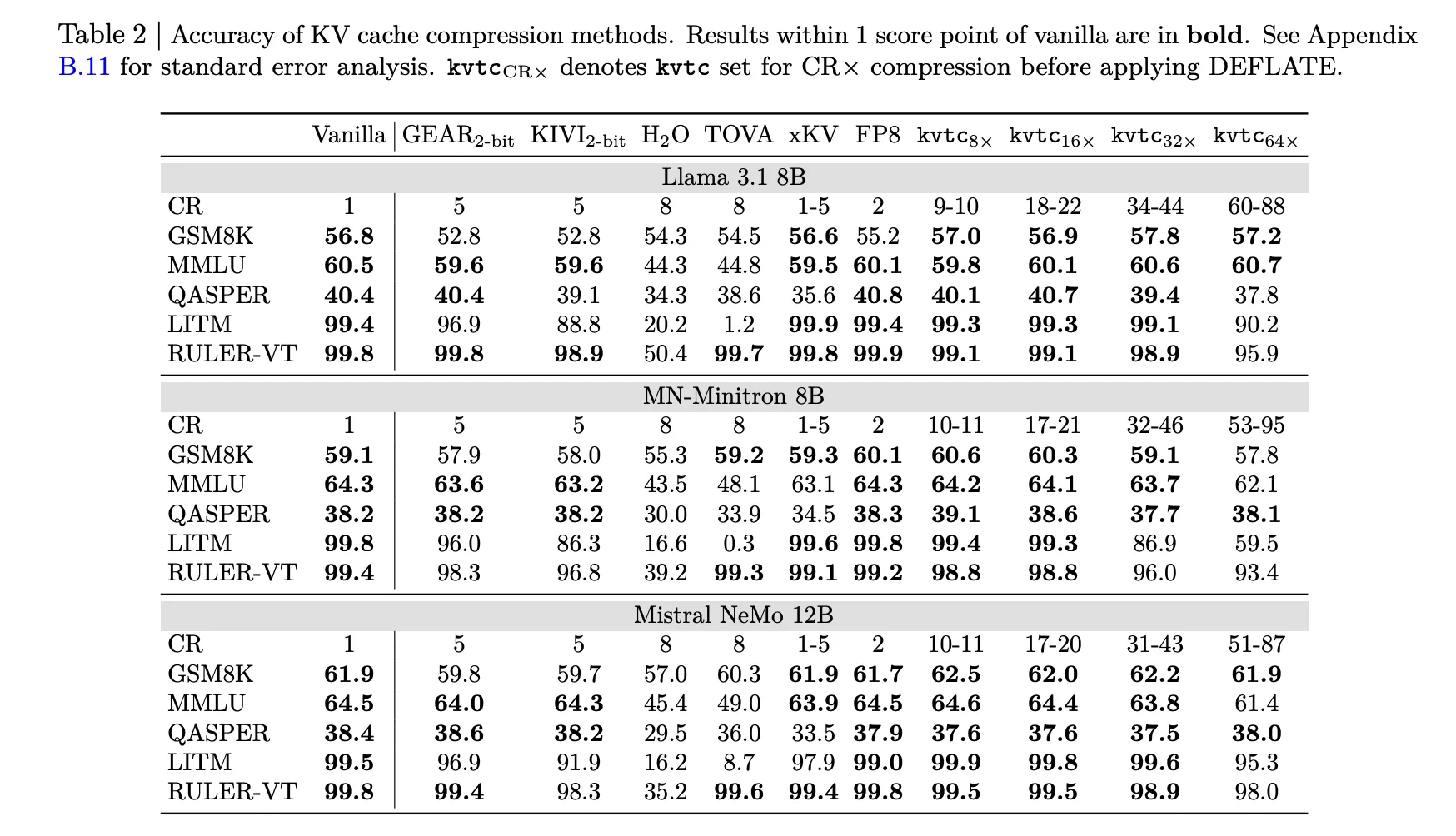
Accuracy: With 16x compression (roughly 20x after DEFLATE), the mannequin persistently maintains outcomes inside 1 rating level of the vanilla mannequin. TTFT discount: For 8K context size, kvtc can scale back Time-To-First-Token (TTFT) by as much as 8x in comparison with a full recomputation. Velocity: Calibration is quick. The 12B mannequin will be accomplished in lower than 10 minutes on an NVIDIA H100 GPU. Storage overhead: The extra information saved per mannequin is small, representing solely 2.4% of the mannequin parameters in Llama-3.3-70B.
KVTC is a sensible constructing block for offering memory-efficient LLM providers. The mannequin weights will not be modified and is immediately appropriate with different token elimination strategies.
Vital factors
Excessive compression with low precision loss: KVTC achieves 20x compression over commonplace whereas maintaining outcomes inside one rating level of vanilla (uncompressed) fashions on most inference and long-context benchmarks. Rework Coding Pipeline: This technique makes use of a classical media compression-inspired pipeline that mixes PCA-based function decorrelation, adaptive quantization with dynamic programming, and reversible entropy coding (DEFLATE). Important Token Safety: To keep up mannequin efficiency, KVTC avoids “sliding window” compression of the 4 oldest “consideration sink” tokens and the 128 latest tokens. Operational Effectivity: The system is “tune-free” and requires solely a easy preliminary calibration (lower than 10 minutes for 12B fashions). This leaves the mannequin parameters unchanged and has minimal storage overhead (solely 2.4% for the 70B mannequin). Important latency discount: By decreasing the quantity of information saved and transferred, KVTC can scale back Time-To-First-Token (TTFT) by as much as 8x in contrast to a whole recomputation of the KV cache for lengthy contexts.
Please see the paper right here. Additionally, be happy to observe us on Twitter. Additionally, do not forget to affix the 100,000+ ML SubReddit and subscribe to our e-newsletter. hold on! Are you on telegram? Now you can additionally take part by telegram.



