




The Most Efficient Approach to Crafting Your Personal AI Productivity System
Key TakeawaysThe most effective AI productiveness system isn't the most important one,…
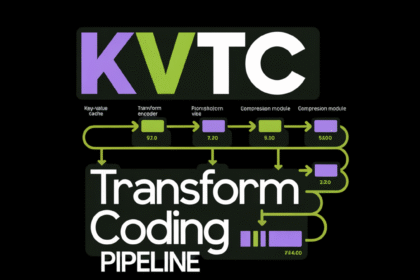
NVIDIA Researchers Introduce KVTC Transform Coding Pipeline to Compress Key-Value Caches by 20x for Efficient LLM Serving
Offering massive language fashions (LLMs) at scale is a significant engineering problem…
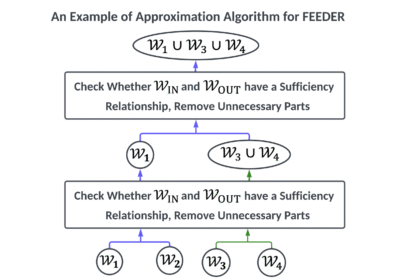
FEEDER: A Pre-Selection Framework for Efficient Demonstration Selection in LLMs
LLMS demonstrates distinctive efficiency throughout a number of duties by using a…
