



Mito Labs has launched MitoTTS, an open-weight 8 billion parameter text-to-speech mannequin. Generate expressive speech from each textual content and audio context. This mannequin makes use of residual vector quantization (RVQ) to increase the vary of sounds. This permits us to keep away from scaling a single flat vocabulary whereas protecting the variety of parameters fastened.
What’s Miso TTS?
MitoTTS is a text-to-dialog RVQ transformer with 8B parameters. It’s impressed by the Sesame CSM structure. It combines an Llama 3.2 fashion spine with a small audio decoder. Generates Mimi audio code from textual content and elective audio context. The mannequin is conditional on each textual content and former audio. The second enter permits it to react to the tone of the speaker.
The textual content vocabulary is 128,256 tokens with 32 phonetic codebooks. Mimi is an audio tokenizer with a most sequence size of two,048. Default inference is carried out on torch.bfloat16.
Mito Labs claims a latency of 110ms. Eleven Lab is listed at 700 ms and Sesame at 300 ms.
Vocabulary dimension problem
Customary transformers generate from a hard and fast vocabulary of discrete tokens. This works when a small vocabulary covers the goal space. Human speech does not match that assumption. It relies on pitch, rhythm, emphasis, emotion, and accent.
Rising your vocal vocabulary is the plain resolution. Nonetheless, because the vocabulary grows, the usual transformer requires extra parameters. Every token should be represented and predicted by the mannequin. At Mito Labs, we name this the vocabulary dimension downside.
The second problem is conditioning. Most TTS fashions situation solely on textual content. They ignore the tone of the interlocutor. Mito Labs claims this contributes to the “uncanny valley” impact.
Residual Vector Quantization: The Core Thought
MitoTTS addresses each issues associated to residual vector quantization (RVQ). Mito Labs traces RVQ again to Sesame’s CSM for picture technology analysis and audio. As an alternative of 1 token index, the mannequin outputs a vector of indices.
Every audio token is a 32 codebook index spanning a 2048-way codebook. The mannequin maintains a separate codebook for every place inside the vector. To recuperate the sound, sum the searched vectors. Every codebook provides additional refinements to the sign.
That is what makes scaling work. The addressable vocabulary is the same as the codebook dimension expanded in depth. Rising the depth doesn’t add any parameters to the mannequin. Due to this fact, MisoTTS quantities to roughly 204832, or roughly 10105 addressable tokens. Mito Labs factors out that easy scaling would require a a lot bigger community.
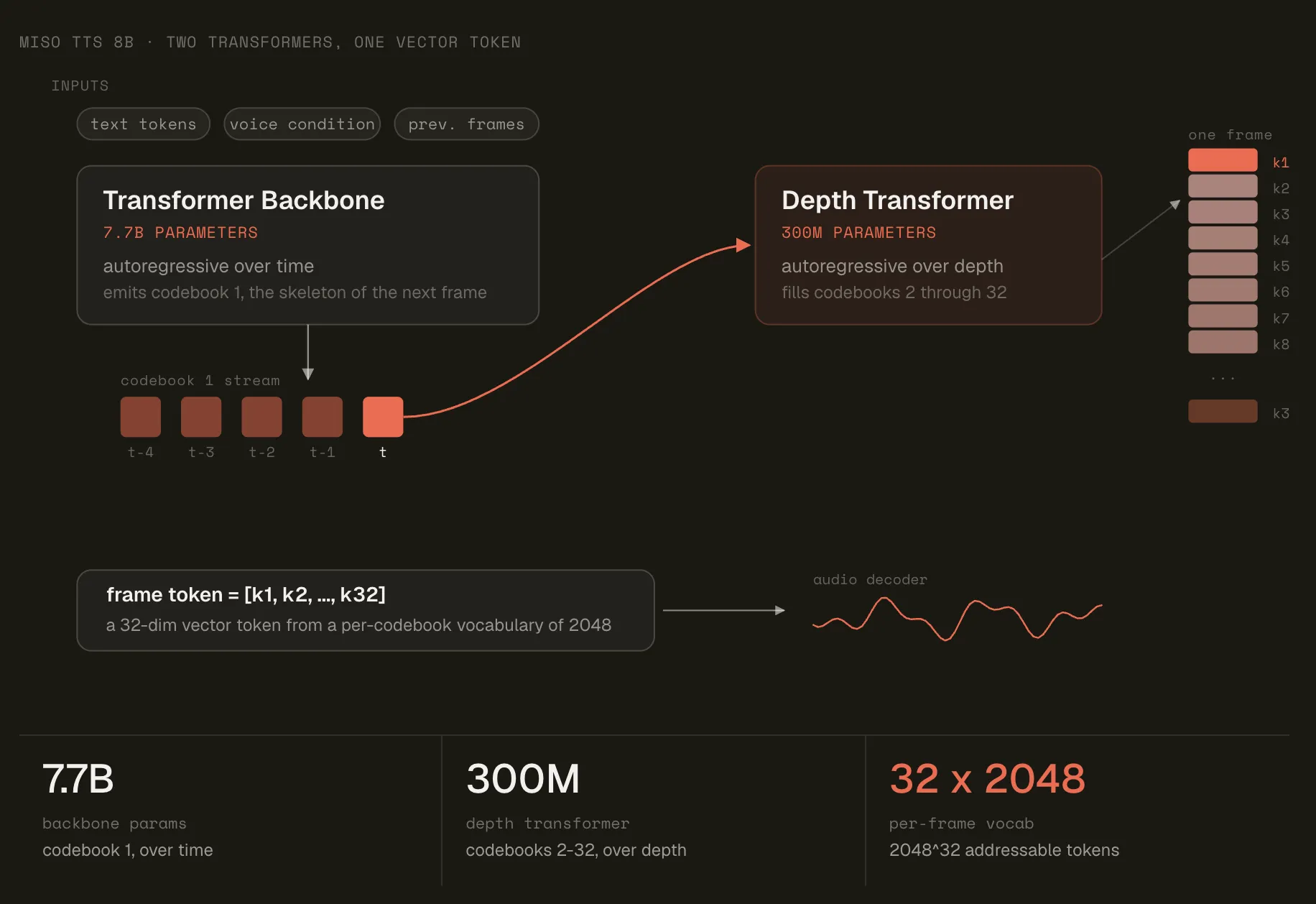
Two transformer structure
The mannequin is cut up right into a spine and a decoder. The spine is a 7.7B parameter transformer that’s autoregressive over time. Predict the preliminary codebook index and closing hidden state.
A 300M parameter decoder is then run autoregressively over depth. Predict the remaining codebook indices one place at a time. Every prediction is conditioned on the index already chosen within the body. The identical 300M parameters are reused in all positions.
Embedding follows the identical logic. Textual content tokens use a single lookup. The audio token embedding is the sum of codebook lookups per place. Interleaving textual content and audio permits for using dialog historical past within the spine. That is the way you convey context throughout turns.
Strengths and challenges
Strengths:
Open weight on the primary day underneath the modified MIT license. RVQ scales the vary of sounds with out scaling the variety of parameters. Circumstances associated to the audio context fairly than the textual content alone. Native deployments maintain delicate voice knowledge on-premises. Structure and arithmetic are coated in public weblog posts.
task:
Half duplex solely, no flip taking but. Bigger fashions require succesful CUDA GPUs. API entry has been introduced however not but obtainable. Latency and high quality claims nonetheless require third-party testing.
Visible rationalization of Marktechpost
Marktechpost · Mannequin briefs
01/09
Indiscriminate Weight Launch · June 3, 2026
Miso TTS
Miso Labs’ 8B emotional text-to-speech mannequin constructed on residual vector quantization and conditioned on each textual content and speech.
8B Parameter
RVQ transformer
mimi code
Modified MIT
What’s Miso TTS?
Textual content to Dialog RVQ Transformer
8B parameter mannequin impressed by Sesame CSM structure. Combines an Llama 3.2 fashion spine with a small audio decoder. Generates Mimi audio code from textual content and elective audio context. Relying on the earlier audio circumstances, the output will reply to speaker tones.
At a look
Revealed specs
parameters
8B (7.7B + 300M)
structure
RVQ transformer
audio code e book
32 (2048-way)
default precision
torch.bfloat16
motive
Vocabulary rely downside
Transformers generate from a hard and fast vocabulary of discrete tokens. Speech varies in pitch, rhythm, emphasis, emotion, and accent. Bigger audio vocabularies require extra parameters in normal transformers. Most TTS circumstances are text-only and ignore tones. — “Uncanny Valley” impact.
core thought
Residual vector quantization
The mannequin outputs a vector of indices fairly than a single token index. Every token is a 32 codebook index spanning a 2048-way codebook. The sound is reconstructed by summing the searched vectors. Depth scales the addressable vocabulary to ~204832 (≈10105) with none extra parameters.
structure
2 Transformers, 1 Vector Token
Spine (7.7B) — Autoregressive over time. Predict the codebook index k₁ and hidden state h₀. Decoder (300M) — Autoregressive over depth. Predict k₂ to k₃₂. The identical 300M parameters are reused in all positions. Interleaved textual content and audio permits dialog historical past for use within the spine.
run domestically
Reasoning in just a few strains
from generator import load_miso_8b
import torchaudio gen =load_miso_8b(system=“Cuda”model_path_or_repo_id=“MisoLabs/MisoTTS”) audio = gen.generate( textual content=“Hi there from Myso.”speaker =0context =[]max_audio_length_ms=10_000) torchaudio.save(“Miso.wav”audio.unsqueeze(0).cpu(), gen.sample_rate)
The setup makes use of uv with Python 3.10. Obtain the weights from Hugging Face. By default, SilentCipher watermarks your audio. One-shot audio cloning works from clips which are roughly 10 seconds lengthy.
Restrictions
Simply stopped for now
Processes solely particular person turns. There isn’t a flip but. Generates half-duplex audio. You can not converse whereas the opposite particular person is talking. Mito Labs envisions full duplex and turn-taking as future challenges. API entry has been introduced however not but obtainable.
Necessary factors
brief model
Open weight 8B TTS underneath the modified MIT license. Relying on the textual content and audio circumstances, the output tracks the tone of the speaker. RVQ extends the vocabulary as much as 204832 with out including any parameters. 7.7B spine over time, 300M decoder over depth. At the moment half-duplex and single-turn. API entry is pending.
Necessary factors
Mito Labs has open sourced MitoTTS, an 8B text-to-speech mannequin, underneath the modified MIT License. Make the technology react in line with the speaker’s tone, conditional on each textual content and audio context. Residual vector quantization (32 codebooks × 2048 methods) scales the vocabulary to ~2048³² with out including any parameters. The structure splits the 7.7B spine (over time) and the 300M decoder (over depth). At the moment solely half-duplex and single-turn. API entry remains to be pending.
Test mannequin weights, repositories, and technical particulars. Additionally, be happy to observe us on Twitter. Additionally, remember to hitch the 150,000+ ML SubReddit and subscribe to our e-newsletter. grasp on! Are you on telegram? Now you can additionally take part by telegram.
Must associate with us to advertise your GitHub repository, Hug Face Web page, product releases, webinars, and extra? Join with us


