



MiniMax has launched MSA (MiniMax Sparse Attendance), a sparse consideration methodology constructed straight on Grouped Question Consideration (GQA). It targets one bottleneck: the quadratic value of softmax consideration in lengthy contexts. The MiniMax analysis workforce examined inside a 109B parameter professional combination mannequin educated on native multimodal knowledge. We additionally open sourced our inference kernel and shipped the product mannequin MiniMax-M3.
What’s MSA (MiniMax Sparse Consideration)?
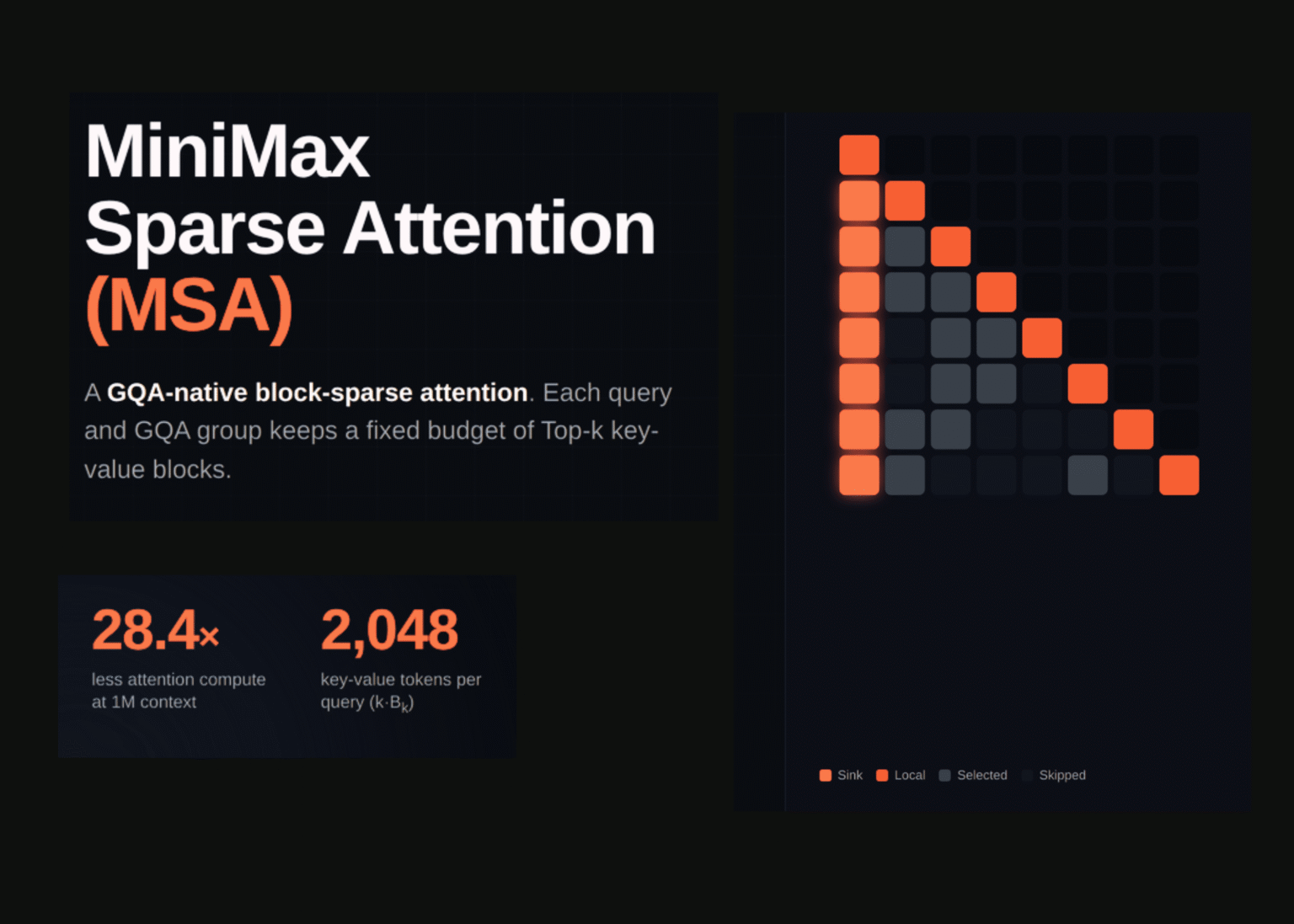
MSA (MiniMax Sparse Attendance) divides consideration into two levels: index department and most important department. Index branches decide which blocks of keys and values every question reads. The primary department then performs actual softmax consideration solely on these blocks.
Choice is completed at block granularity, not token by token. The default block measurement is Bk = 128 tokens. Every question and GQA group holds ok = 16 blocks. This fixes the finances per question to kBk = 2,048 key-value tokens.
The 2 have completely different value constructions. Dense GQA consideration scales O(N) per question, i.e. as an entire context. The MSA scales as O(kBk) and stays mounted as N will increase. Subsequently, the computing hole widens because the context size will increase.
Choice is shared inside every GQA group, however impartial between teams. One key/worth head corresponds to a number of question heads, which share one set of blocks. Totally different teams can take part in numerous lengthy distance areas.
How the 2 branches work
The index department provides solely two projection matrices to the usual GQA layer. Outline one index question head and one shared index key head for every GQA group. Rating seen key tokens and max-pool these scores to the block stage.
The High-k operator then selects the best scoring block for every question and group. Native blocks containing queries are at all times included. This prevents the selector from eradicating the fast neighborhood of the question.
The Principal Department collects causally seen tokens from the chosen blocks. Apply a restricted scaled dot product softmax consideration to those tokens. Every question head maintains its personal question projection, however shares the group’s set of blocks.
The visualization within the report reveals the alternatives made by the realized indexer. The top concentrates on the native diagonal and the primary block. They save the remainder of their finances for some lengthy distance stripes.
Tips on how to prepare MSA
Because the High-k choice is non-differentiable, the index projection can’t be educated by language modeling loss. MSA solves this via KL alignment loss. The loss matches the distribution of the index department and the featured sample of the principle department. The trainer is the principle department distribution of the group imply over the chosen tokens.
Three mechanisms stabilize sparse coaching. Gradient Detach applies a stop-gradient to the index department enter. This limits the KL loss to the exponential prediction reasonably than the spine. With out this, massive KL coefficients would lead to slope spikes and loss divergence.
Indexer warmup is carried out with utmost care on each branches within the first iteration. The indexer learns from the KL loss earlier than controlling the routing. Pressure native blocking reserves one slot for close by contexts.
Ablation shaped the ultimate recipe. An earlier variant added an Index Department worth head with its personal output. With warm-up, you do not want that worth head anymore. The ultimate design removes it for effectivity causes.
MSA helps two coaching routes. MSA-PT trains from scratch after warming up the indexer for 40B tokens. MSA-CPT converts dense GQA checkpoints educated on 2.6T tokens. It then continues for 400B tokens, together with a warm-up 40B token.
Kernel co-design
Theoretical sparsity doesn’t translate into pace with out matching GPU paths. MSA combines the algorithm with the concept of two kernels.
The primary is a High-k choice with no expertise factors. Softmax preserves order, so rating the uncooked scores yields similar indices. The kernel skips the max, exp, and sum steps earlier than choice. It ran 5.1x quicker than torch.topk on a 128K context with ok = 16. It additionally outperforms the TileLang radix-select kernel by an element of three.7.
The second is KV exterior sparse consideration with question assortment. Iterating over a KV block will increase the computational depth in comparison with iterating over a question. The kernel packs ⌈128/G⌉ question positions into one 128×128 rating MMA. Two-phase switch divides consideration and combines steps throughout the CTA.
The open supply kernel fmha_sm100 targets NVIDIA SM100 GPUs. It ships a dense FlashAttendant and a sparse High-k kernel underneath the MIT license. Helps BF16, FP8, NVFP4, and FP4 precision.
Comparability of MSA with different sparse strategies
The analysis workforce positions MSA towards 4 natively educated sparse designs.
The desk under summarizes the variations described.
The distinctive pair of MSA is the mix of High-k sharing and block-level choice per GQA group. This retains the KV readings steady whereas giving every group its personal acquisition.
The standard is holding up. Each sparse fashions stay almost as aggressive as the complete consideration baseline.
The desk under reveals typical outcomes for a 3T token finances.
After lengthy context growth, MSA-CPT remained nearly full on HELMET-128K and RULER-128K. Every question nonetheless processes solely 2,048 key-value tokens.


