



This text explains what immediate compression is, why it will be important for agent AI loops, and find out how to implement immediate compression in observe utilizing summarization and crucial distillation.
Subjects lined embrace:
Why agent loops accumulate token prices quadratically and the way immediate compression addresses this. A overview of main immediate compression methods together with instruction extraction, recursive summarization, vector database search, and LLMLingua. A working Python instance that mixes recursive summarization and crucial distillation to realize significant token financial savings.
introduction
Agent loops in manufacturing may be synonymous with excessive prices, particularly relating to each LLM and exterior software utilization through APIs, as billing is intently tied to token utilization.
Excellent news. Immediate compression is without doubt one of the only methods you possibly can implement to keep away from the excessive price of agent loops. This text introduces and explains how varied immediate compression strategies may also help alleviate monetary points when utilizing agent loops.
Speedy compaction: motivations and customary methods
Many agent frameworks, corresponding to LangGraph and AutoGPT, drive the agent to take care of the context of what it has performed in earlier steps. To illustrate an agent must take 10 to twenty steps to resolve an issue. 500 tokens might be despatched to carry out step 1. Step 2 requires you to submit new info particular to this step (roughly 1,000 tokens in whole) along with the earlier 500 tokens. This may enhance to round 1,500 tokens in step 3 and so forth. By the point we attain the twentieth step, we have “paid” for submitting almost the identical info over and over.
Within the instance above, it could seem that the variety of tokens despatched per step (the general dimension of the immediate) will increase linearly. Nevertheless, in actuality, the cumulative price of your entire agent loop is quadratic fairly than linear, and the price will increase exponentially the longer the loop continues. That is the place instantaneous compression strategies, utilizing methods corresponding to selective context, summarization, come in useful, as we’ll see shortly.
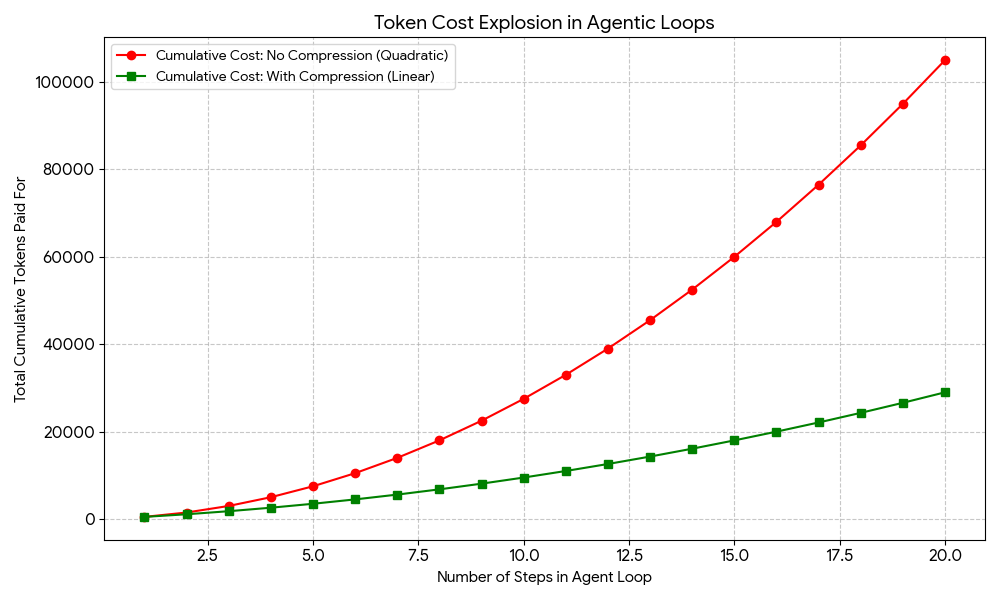
Instance agent loop price curves with out and with immediate compression
This concern is not only monetary. There may be additionally one other hidden price related to latency, as lengthy prompts take longer to course of and never all customers wish to wait 30 seconds for every interplay. Compressed prompts pace up inference and scale back computational overhead.
To place this in perspective, you might theoretically scale back a 500K token context to a 32K token compression window that retains all related info, however removes parts corresponding to repetitive JSON constructions, cease phrases, and low-value dialog items. Listed below are some cost-effective options and frameworks you possibly can take into account to implement your personal immediate compression technique.
Instruction extraction: This consists of making a “compressed” model of a protracted system immediate that’s despatched repeatedly, containing symbols and shorthand that the mannequin understands and interprets. Recursive summarization: Each few steps within the loop, use an agent or a small, cheap mannequin like Llama 3 or GPT-4o-mini to summarize the context of the earlier step right into a extra concise paragraph that outlines the present state of the duty. Vector Database for Historical past Retrieval (RAG): This shops the whole historical past in a free native vector database, corresponding to FAISS or Chroma, as a substitute of sending it over and over. For a given immediate, solely probably the most related actions are captured as a part of the context. LLMLingua: A well-liked open-source framework targeted on detecting and eradicating “unimportant” tokens in prompts earlier than being despatched to bigger, dearer language fashions.
Sensible instance: abstract agent
Beneath is an instance of a cost-friendly immediate compaction technique that mixes recursive summarization and instruction extraction utilizing Python. This code is meant to function a template to point out what such immediate compression logic would appear like when translated right into a real-world large-scale state of affairs. This reveals a simplified simulation of the agent loop, highlighting the summarization and distillation steps.
import tiktoken def count_tokens(textual content, mannequin=”gpt-4o”): encoding = tiktoken.encoding_for_model(mannequin) return len(encoding.encode(textual content)) def compress_history(history_list): “”” Operate that simulates a “abstract”. In an actual app, you’ll ship the enter to a small language mannequin (corresponding to gpt-4o-mini) and print(“— historical past compression —“) # In manufacturing, you’ll cross ‘mixed’ to the summarization mannequin combed = ” “.be a part of(history_list) # Distill: shortened model of occasion abstract = f”{len(history_list)} Step abstract: Duties A and B accomplished. ” return abstract # 1. Extracted system immediate (use shorthand as a substitute of prose) system_prompt = “Act: ResearchBot. Activity: Discover X. Output: JSON solely. Constraints: No fluff. ” # 2. Historical past of Agentic Loop = []raw_token_total = 0 for step in vary(1, 6): motion = f”Step {step}: The agent carried out a really time-consuming search on information level {step}…” Historical past.append(motion) # Compute what the immediate would appear like with out compression current_full_context = system_prompt + ” “.be a part of(historical past) raw_tokens = count_tokens(current_full_context) print(f”Loop {step} | Full context tokens: {raw_tokens}”) # 3. Making use of compression crash_context = system_prompt + compress_history(historical past) crash_tokens = count_tokens(compressed_context) print(f”nFinal uncompressed tokens: {raw_tokens}”) print(f”Ultimate compressed tokens: {compressed_tokens}”) print(f”Financial savings: {((raw_tokens – compressed tokens) / raw_tokens) * 100:.1f}%”)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
twenty one
twenty two
twenty three
twenty 4
twenty 5
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import tick token
absolutely count_tokens(sentence, mannequin=“gpt-4o”):
encoding = tick token.Mannequin encoding(mannequin)
return Ren(encoding.encode(sentence))
absolutely Compression historical past(historical past listing):
“””
Skill to simulate a “abstract”. Within the precise app,
I have to ship enter to a small language mannequin.
Compress it (like gpt-4o-mini).
”“”
print(“— Compressing historical past —“)
# In manufacturing, cross “mixed” to the abstract mannequin
mixed = “”.take part(historical past listing)
# Distillation: shortened model of the occasion
abstract = f“{len(history_list)} Step Abstract: Duties A and B accomplished. Consequence: Success.”
return abstract
# 1. Extracted system prompts (use shorthand as a substitute of prose)
system immediate = “Motion: ResearchBot. Activity: Seek for X. Output: JSON solely. Constraints: No fluff.”
#2. Agent loop
historical past = []
raw_token_total = 0
for step in vary(1, 6):
motion = f“Step {step}: The agent carried out a really lengthy seek for information level {step}…”
historical past.add(motion)
# Calculate what the immediate would appear like with out compression
current_full_context = system immediate + “”.take part(historical past)
raw_token = count_tokens(current_full_context)
print(f“Loop {step} | Full context tokens: {raw_tokens}”)
#3. Apply compression
compression context = system immediate + Compression historical past(historical past)
compressed token = count_tokens(compression context)
print(f“nFinal uncompressed tokens: {raw_tokens}”)
print(f“Ultimate compressed tokens: {compressed_tokens}”)
print(f“Financial savings: {((raw_tokens – COMPLEX_TOKENS) / RAW_TOKENS) * 100:.1f}%”)
This code reveals find out how to periodically substitute a cumulative listing of actions with a abstract spanning a single string, serving to to keep away from the extra price of paying for a similar context token on every loop iteration. Strive performing the summarization step utilizing a smaller, cheaper mannequin, or an area mannequin corresponding to Llama 3.
Concerning distillation, the next instance reveals what it really does.
A typical 42-token immediate: “You’re a useful analysis assistant. Your aim is to search out details about X. Please present your output in legitimate JSON format and don’t embrace dialog fillers.” This may be summarized within the following 12-token immediate: “Act: ResearchBot. Activity: Seek for X. Output: JSON. No fluff.” The mannequin figures it out in a lot the identical method. Think about a loop of 100 steps. This 30-token distinction alone saves you about 3,000 tokens in system prompts alone.
output:
Loop 1 | Full Context Token: 37 Loop 2 | Full Context Token: 55 Loop 3 | Full Context Token: 73 Loop 4 | Full Context Token: 91 Loop 5 | Full Context Token: 109 — Compression Historical past — Ultimate Uncompressed Token: 109 Ultimate Compressed Token: 36 Financial savings: 67.0%
loop 1 | full context token: 37
loop 2 | full context token: 55
loop 3 | full context token: 73
loop 4 | full context token: 91
loop 5 | full context token: 109
—– Compressing historical past —–
last uncompressed token: 109
last compressed token: 36
financial savings: 67.0%
abstract
Prompt compression isn’t a small optimization. That is virtually essential for agent methods that carry out various steps. The methods mentioned right here, from instruction distillation and recursive summarization to RAG-based historical past search and LLMLingua, every deal with the quadratic price downside from a distinct angle and may be mixed to ship even higher financial savings. As a place to begin, recursive summarization mixed with extracted system prompts requires no extra infrastructure and may already considerably scale back token utilization, as the instance above reveals.

