



LLMS demonstrates distinctive efficiency throughout a number of duties by using a small variety of shot inference, also called context studying (ICL). The principle drawback lies in deciding on essentially the most consultant demos from a big coaching dataset. The preliminary technique used similarity scores between every instance and enter query to pick out demonstrations primarily based on their affiliation. The present technique means that extra choice guidelines ought to be used along with similarity to extend the effectivity of demonstration choice. These enhancements lead to vital calculation overhead because the variety of pictures will increase. As completely different LLMs exhibit completely different options and information domains, the effectiveness of the chosen demo must also be thought-about for the precise LLMs in use.
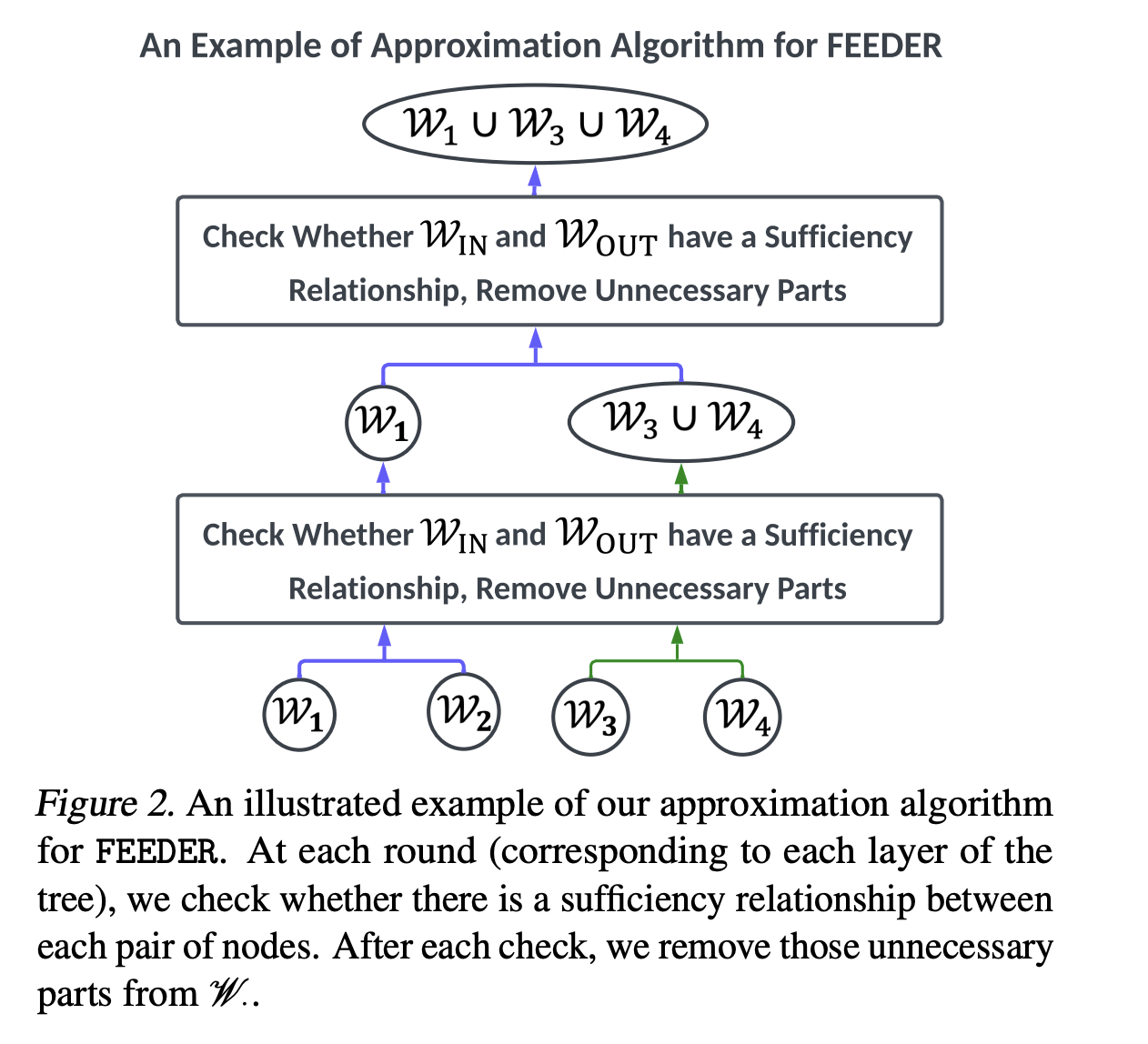
Researchers from Shanghai Jiao Tong College, Xiaohongshu Inc., Carnegie Mellon College, Peking College, No Affiliation, College School London, and the College of Bristol have proposed feeders (nonetheless essential demonstration preselectors). To assemble this subset, “adequate” and “wanted” metrics are launched within the earlier choice stage, together with tree-based algorithms. Moreover, the feeder reduces coaching information dimension by 20% whereas sustaining efficiency and seamlessly integrates with numerous downstream demonstration choice strategies for ICL throughout LLMSs starting from 300m to 8B parameters.
The feeder is evaluated on six textual content classification datasets: SST-2, SST-5, COLA, TREC, SUBJ, and FPB, overlaying duties starting from sentiment classification and linguistic evaluation to textual content entanglement. It has additionally been evaluated for the inference dataset GSM8K, the semantic passing dataset SMCALFLOW, and the scientific query dataset GPQA. The official splits for every dataset are straight tracked to seize coaching and take a look at information. Moreover, a number of LLM variants are used, together with two GPT-2 variants, GPT-NEO with 1.3B parameter, GPT-3 with 6B parameter, GPT-3 with 2B parameter, GEMMA-2 with 7B parameter, LLAMA-2 with 8B parameter, LLAMA-2 with 8B parameter, and LLAMA-2 with 32B parameter.
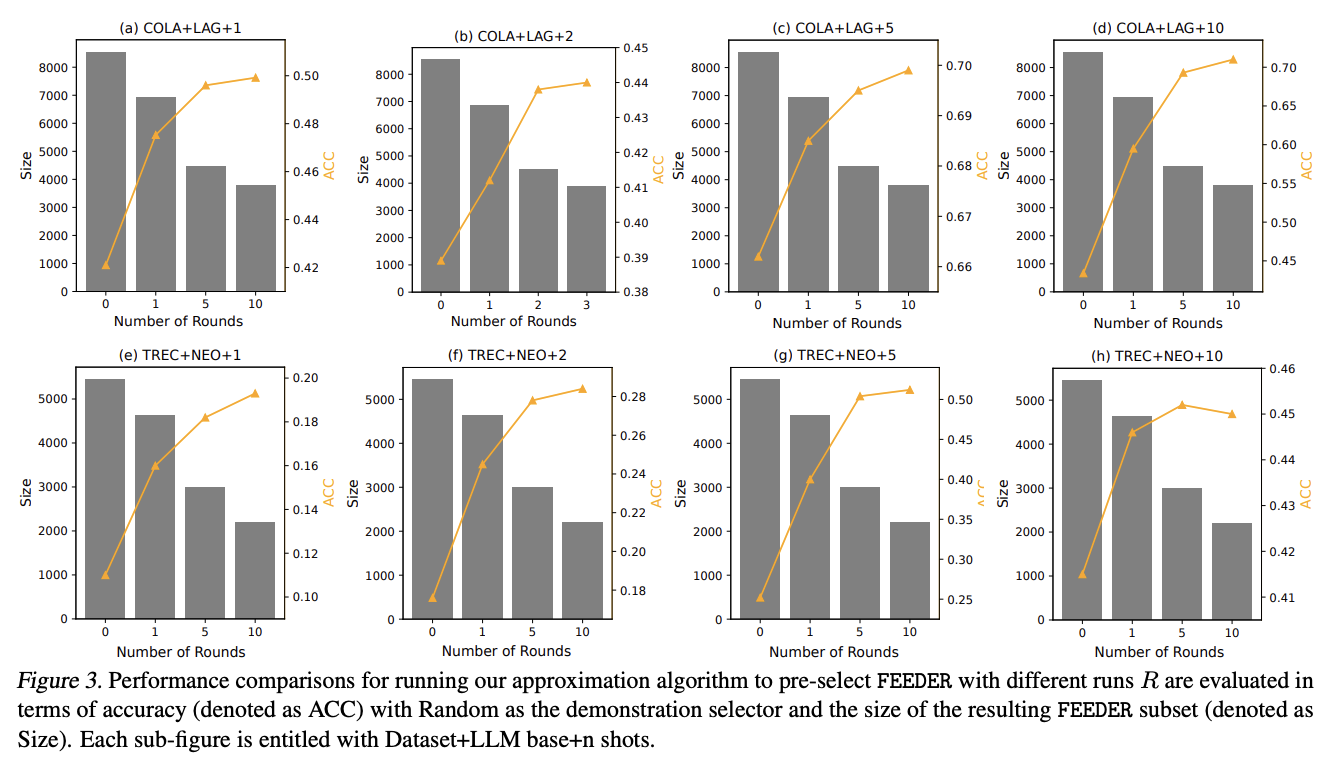
Outcomes on studying efficiency throughout the context present that feeders can obtain good or comparable efficiency whereas permitting them to retain almost half of the coaching pattern. Analysis of a small variety of shot efficiency on advanced duties utilizing LLMs like Gemma-2 exhibits that feeders enhance efficiency even when LLMS struggles with difficult duties. It really works successfully on many pictures. Sometimes, conditions the place LLM efficiency is degraded when rising from 5 to 10 because of noisy or repeated demonstrations. Moreover, feeders assist to make sure efficiency stability of LLM by assessing the sufficiency and want for every demonstration.
With bi-level optimization, feeders make the most of small, high-quality datasets for fine-tuning, whereas concurrently lowering computational prices and enhancing efficiency to match core set choice ideas. The outcomes present that fine-tuning LLMS affords larger efficiency enhancements in comparison with enhancing LLMS in context, and that feeders obtain even higher efficiency enhancements in fine-tuning settings. Efficiency evaluation reveals that feeder effectiveness will increase first after which decreases because the variety of runs or rounds will increase, confirming that LLM efficiency improves by figuring out consultant subsets from the coaching dataset. Nonetheless, an excessively slim subset can restrict potential efficiency enhancements.
In conclusion, the researchers have launched feeders, a pre-selector for demonstrations designed to make use of LLM options and area information to establish high-quality demonstrations via an environment friendly discovery strategy. It reduces coaching information necessities and supplies a sensible resolution for environment friendly LLM deployments whereas sustaining comparable efficiency. Future analysis instructions embrace exploring functions with massive LLM and increasing feeder capabilities to areas resembling information security and information administration. Feeders make a priceless contribution to demonstration selection and supply researchers and practitioners with efficient instruments to optimize LLM efficiency whereas lowering computational overhead.
Try the paper. All credit for this examine will likely be directed to researchers on this venture.
Meet the AI Dev e-newsletter learn by Nvidia, Openai, Deepmind, Meta, Microsoft, JP Morgan Chase, Amgen, Aflac, Wells Fargo, 100s 40k+ Devs and researchers [SUBSCRIBE NOW]

Sajjad Ansari is the ultimate 12 months of IIT Kharagpur. As a know-how fanatic, he delves into sensible functions of AI, specializing in understanding the impression of AI know-how and its real-world that means. He goals to make clear advanced AI ideas in clear and accessible methods.

