



A number of years in the past, after I was working as a advisor, I used to be deriving comparatively complicated ML algorithms, however I used to be going through the problem of creating the inner mechanisms of that algorithm clear to stakeholders. At the moment, I first began utilizing parallel coordinates. As a result of it is easy to visualise the relationships between 2, 3, 4, 5. Nonetheless, as quickly as you start working with vectors of upper dimension vectors (e.g., e.g., e.g.), the human thoughts typically fails to know this complexity. Enter parallel coordinates: It is a quite simple but efficient device that I typically surprise why it is not utilized in on a regular basis EDA (besides my workforce). Due to this fact, on this article we share some great benefits of parallel coordinates based mostly on wine datasets. We spotlight how this method can assist to disclose correlations, patterns, or clusters of information with out dropping practical semantics (e.g. PCA).
What are parallel coordinates?
Parallel coordinates are a standard option to visualize high-dimensional information units. And sure, that is technically appropriate, however this definition doesn’t totally seize the effectivity and magnificence of this technique. Not like commonplace plots, the place there are two orthogonal axes (and thus two dimensions that may be plotted), in parallel coordinates there are as many vertical axes because the dataset has dimensions. Because of this observations could be displayed as strains throughout all axes with corresponding values. Do you need to be taught some flashy phrases that can contact you at your subsequent hackathon? “Polyline” is the proper time period. The sample is then displayed as a bundle of polyrins with comparable conduct. Or, extra particularly, clusters are displayed as bundles, whereas correlations are displayed as trajectories with a constant gradient on adjoining axes.
Would not they simply do PCA (main part evaluation)? Parallel coordinates protect all unique performance. In different phrases, it doesn’t condense data and challenge it into low-dimensional house. Due to this fact, it will ease many interpretations for each you and your stakeholders! However (sure, throughout all the thrill, it nonetheless needs to be…) you must watch out to not fall into extreme traps. When you do not put together the info rigorously, parallel coordinates is not going to be learn simply. Present your walkthrough that function choice, scaling and readability changes are extraordinarily useful.
by the way in which. Right here we have to point out Professor Alfred Inzelberg. It was an honor to have dinner with him in Berlin in 2018. He’s the one who made me loopy about parallel coordinates. He’s additionally the godfather of parallel coordinates, demonstrating his worth in quite a few use circumstances within the Nineteen Eighties.
Show my factors with a wine dataset
For this demo, we selected a wine dataset. why? To start with, I like wine. Secondly, I requested ChatGpt for a public dataset much like one of many firm’s datasets I am at present engaged on (and I did not need to take all the trouble and publicly/anonymize/… to get firm information). Third, this dataset is effectively studied in lots of ML and analytical functions. It accommodates information from an evaluation of 178 wines grown by three grape varieties in the identical area of Italy. Every statement has 13 consecutive attributes (suppose alcohol, flavonoid focus, proline content material, coloration depth, and many others.). The goal variable is the grape class.
We’ll present you tips on how to load a dataset into Python to observe by.
Import PDAS as PDAS #UCI Load the wine dataset for “https://archive.ics.uci.edu/ml/machine-learning-database/wine/wine.information” of. [
“Class”, “Alcohol”, “Malic_Acid”, “Ash”, “Alcalinity_of_Ash”, “Magnesium”,
“Total_Phenols”, “Flavanoids”, “Nonflavanoid_Phenols”, “Proanthocyanins”,
“Color_Intensity”, “Hue”, “OD280/OD315”, “Proline”
]
#Dataset df = pd.read_csv(uci_url,header = none,names = col_names) Load df.head()
good. Now let’s derive naive plots as baselines.
First Step: Constructed-in Panda
Let’s use the built-in panda plot perform:
pandas.plotting parallel_coordinates matplotlib.pyplot is plt plt.determine(figsize = (12,6))paralled_coordinates(df, ‘class’, ‘viridis’)plt.title(“parallel adjustment = PLT.
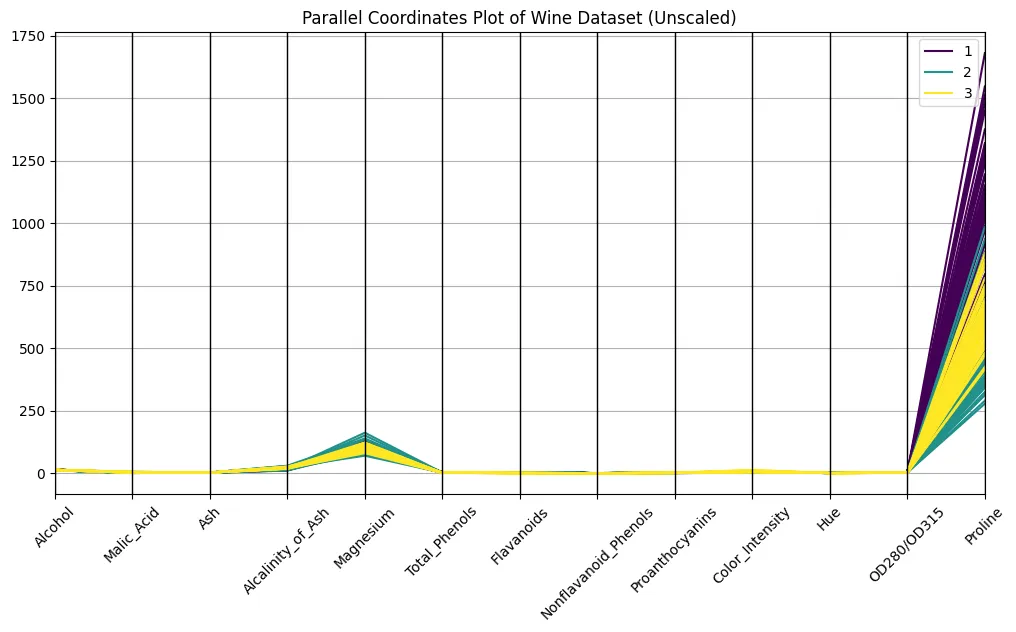
Seems to be good, does not it?
No, it is not. It’s actually potential to establish courses on the plot, however variations in scaling make it troublesome to match throughout axes. For instance, evaluate the scale of Proline and Hue. Proline has a robust optical benefit for scaling. The unprotected plot appears virtually meaningless and a minimum of very troublesome to interpret. Nonetheless, it seems that a faint bundle seems to be showing within the class, so let’s promise this to go on for one thing that goes on sooner or later…
It is all scale
A lot of you (everybody?) are accustomed to MIN-MAX scaling from the ML preprocessing pipeline. So, let’s not use it. Standardize the info. So we do Z-scaling right here (every perform has a median of zero and unit variance, with all axes of the identical weight.
sklearn.preprocessing Import StandardScaler # Particular person and Goal Options = df.drop(“class”,axis=1) scaler = stardescaler() scaled = scaler.fit_transform(function)[“Class”] = df[“Class”]
plt.determine(figsize=(12,6)) parallel_coordinates(scaled_df, ‘class’, colormap=’plasma’, alpha=0.5) plt.title(“Parallel coordinate plot (scaling) of wine dataset”) plt.xticks(rotation=45) plt.present()
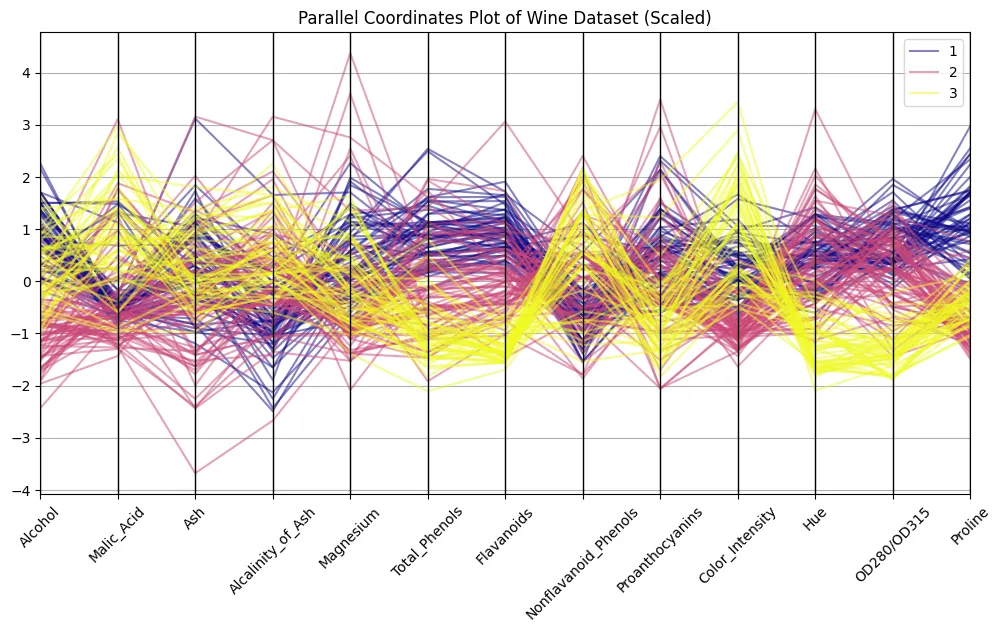
Do you bear in mind the picture from above? The distinction is spectacular, proper? It will can help you establish the sample. Attempt differentiating the clusters of strains related to every wine class to see which options stand out essentially the most.
Operate choice
Have you ever found something? appropriate! I used to be given the impression that alcohol, flavonoids, coloration power and proline largely exhibited textbook type patterns. Filter these and see if function curation helps make your observations much more spectacular.
chosen = [“Alcohol”, “Flavanoids”, “Color_Intensity”, “Proline”, “Class”]
plt.determine(figsize =(10,6)) parallel_coordinates(scaled_df[selected]’class’, colormap = ‘coolwarm’, alpha = 0.6) plt.title (“parallel coordinate plot of chosen options”) plt.xticks (Rotation = 45) plt.present()
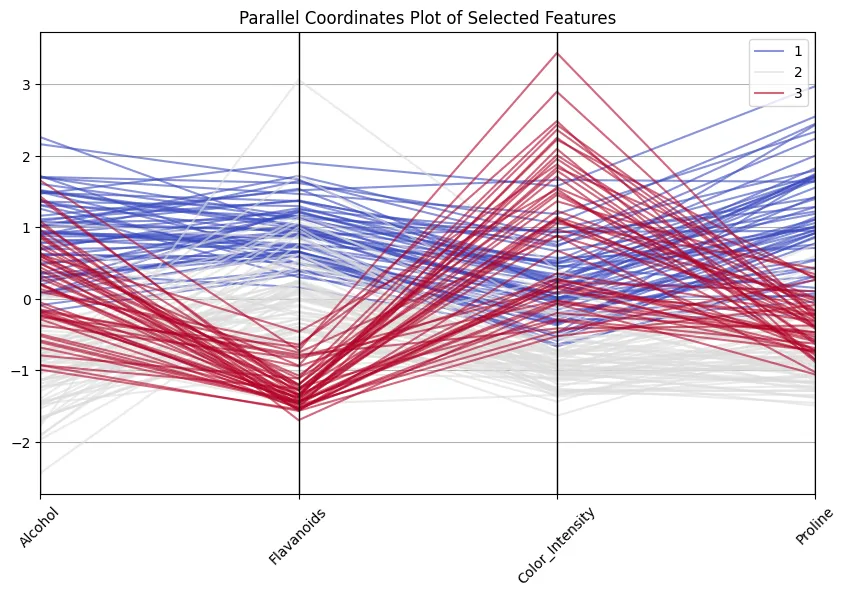
We present that class 1 wines all the time rating excessive on flavonoids and proline, whereas class 3 wines have low coloration power, though they’re low on these! And do not suppose that is a waste of train… Though 13 dimensions are nonetheless nice to course of and examine, I’ve come throughout circumstances of dimensions over 100, and reducing dimensions are important.
Including interactions
I admit: the above instance may be very mechanical. When writing the article, I positioned the hue subsequent to the alcohol, which disintegrated my neatly proven class. So I moved the colour power subsequent to the flavonoid, which helped. However my goal right here wasn’t to supply the proper copy pasta code. Slightly, we had been to reveal using parallel coordinates based mostly on some easy examples. In actual life, arrange a extra exploratory front-end. For instance, parallel coordinates of plots include a “brushing” function. You’ll be able to choose subsections for an axis, and all polylines inside that subset are highlighted.
You can even merely drag and drop to reorder the axis. This typically helps to disclose hidden correlations in default order. Tip: Attempt adjoining axes that you just suspect are covariant.
Higher but, no scaling is required to examine the info within the plot. The axis is mechanically scaled to the minimal and most values for every dimension.
This is the code to breed in your colab:
px## as plotly.Specific holds the category as a separate column. Plotly’s ParCodds expects numeric colours in “coloration” DF[“Class”] = df[“Class”].astype(int) fig_all = px.parallel_coordinates(df,coloration=”class”, #numeric colormapping(1..3)dimension=function.columns,labels={c:c.change(“_”, “”)scaled_df.columns}, fig_all.update_layt(fig_all.update_layout(“_”, “”perform”) ##The next recordsdata are opened in browser or embedded by way of
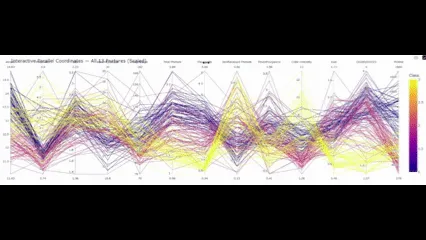
If this remaining factor is in place, what conclusion would you draw?
Conclusion
Parallel coordinates will not be about arduous numbers, however about patterns that come from these numbers. Within the wine dataset, a number of such patterns could be noticed with out performing correlations, PCA, or scattering matrix. Flavonoids strongly distinguish between class 1 and different flavonoids. Coloration depth and hue separate courses 2 and three. Proline strengthens it even additional. What follows not solely permits you to visually separate these courses, but additionally intuitively perceive what really separates the cultivars.
That is actually robust sufficient to exceed T-SNE, PCA, and many others. These strategies challenge information onto elements which can be good at distinguishing courses.
Do not get me fallacious: parallel coordinates will not be Eda’s Swiss Military Knife. You want stakeholders who’ve an excellent grasp of the info in order that they’ll talk utilizing parallel coordinates (in any other case, they may proceed to make use of BoxPlots and Bar charts!). However for you (and me) as an information scientist, parallel coordinates are the microscopes you have all the time dreamed of.
FAQ
A. Parallel coordinates are primarily used for exploratory evaluation of high-dimensional datasets. You’ll find clusters, correlations, and outliers whereas preserving the unique variables interpretable.
A. With out scaling, the options of enormous numerical ranges dominate the plot. Standardize every perform to imply zero, and the variance of models ensures that every one axes contribute equally to the visible sample.
A. PCA and T-SNE scale back dimensions, however the axes lose their unique that means. Parallel coordinates protect semantic hyperlinks to variables on the expense of some confusion and potential overplotting.
![]()
As Fisher’s CDAO, I’m a veteran professional with over 15 years of expertise within the area of information science. In my expertise as a PhD Economics and 5 years of assistant professor of financial concept, I gained a deep understanding of the compliance and impression of social norms on decision-making.
I’m additionally a well known convention speaker and podcast participant, sharing my experience on a variety of subjects associated to information science and enterprise technique. My background consists of working as an AI evangelist for star cooperation and technique and administration consulting with concentrate on after-sales pricing. This expertise has enabled me to develop a variety of skillsets, together with information science, product administration and strategic improvement.
Earlier than the present job, E. He was accountable for managing Breuninger’s large-scale Knowledge Science Middle of Excellence, the place he led a workforce of information scientists and product managers. I’m enthusiastic about utilizing information to drive enterprise selections and obtain concrete outcomes, and I’ve a observe document of success on this space.
With a deep information of economics, psychology and information science, I look ahead to skilled interactions with organizations searching for to drive progress and innovation by data-driven insights.
Log in and proceed studying and luxuriate in professional curated content material.
Proceed studying without spending a dime


