



This text explains how vector databases and graph RAGs differ as reminiscence architectures for AI brokers, and when every strategy is suitable.
Matters coated embrace:
How vector databases retailer and retrieve semantically related unstructured info. How graph RAGs signify entities and relationships for correct multihop search. How to decide on between these approaches or mix them in a hybrid agent/reminiscence structure.
With that in thoughts, let’s get straight to the purpose.
Vector databases and graph RAGs for agent reminiscence: when to make use of which?
Picture by creator
introduction
For AI brokers to be really helpful in advanced multi-step workflows, they want long-term reminiscence. Brokers with out reminiscence are basically stateless capabilities, resetting their context with each interplay. As we transfer towards autonomous techniques managing persistent duties, comparable to a coding assistant monitoring a venture structure or a analysis agent compiling an ongoing literature assessment, the query of how context is saved, retrieved, and up to date turns into necessary.
Presently, the trade normal for this job is vector databases, which use dense embeddings for semantic search. Nevertheless, as the necessity for extra advanced inference will increase, graph RAGs, that are architectures that mix data graphs and huge language fashions (LLMs), are gaining consideration as a structured reminiscence structure.
At first look, vector databases are perfect for broad similarity matching and looking unstructured knowledge, however graph RAGs are higher when the context window is restricted or when multihop relationships, factual accuracy, and complicated hierarchical buildings are required. This distinction highlights the main focus of vector databases on versatile matching in comparison with the power of graph RAGs to purpose via express relationships and keep accuracy beneath tighter constraints.
To make clear their respective roles, this text critiques the underlying concept, sensible strengths, and limitations of each approaches to agent reminiscence. Doing so supplies a sensible framework to information you in selecting which system or mixture of techniques to deploy.
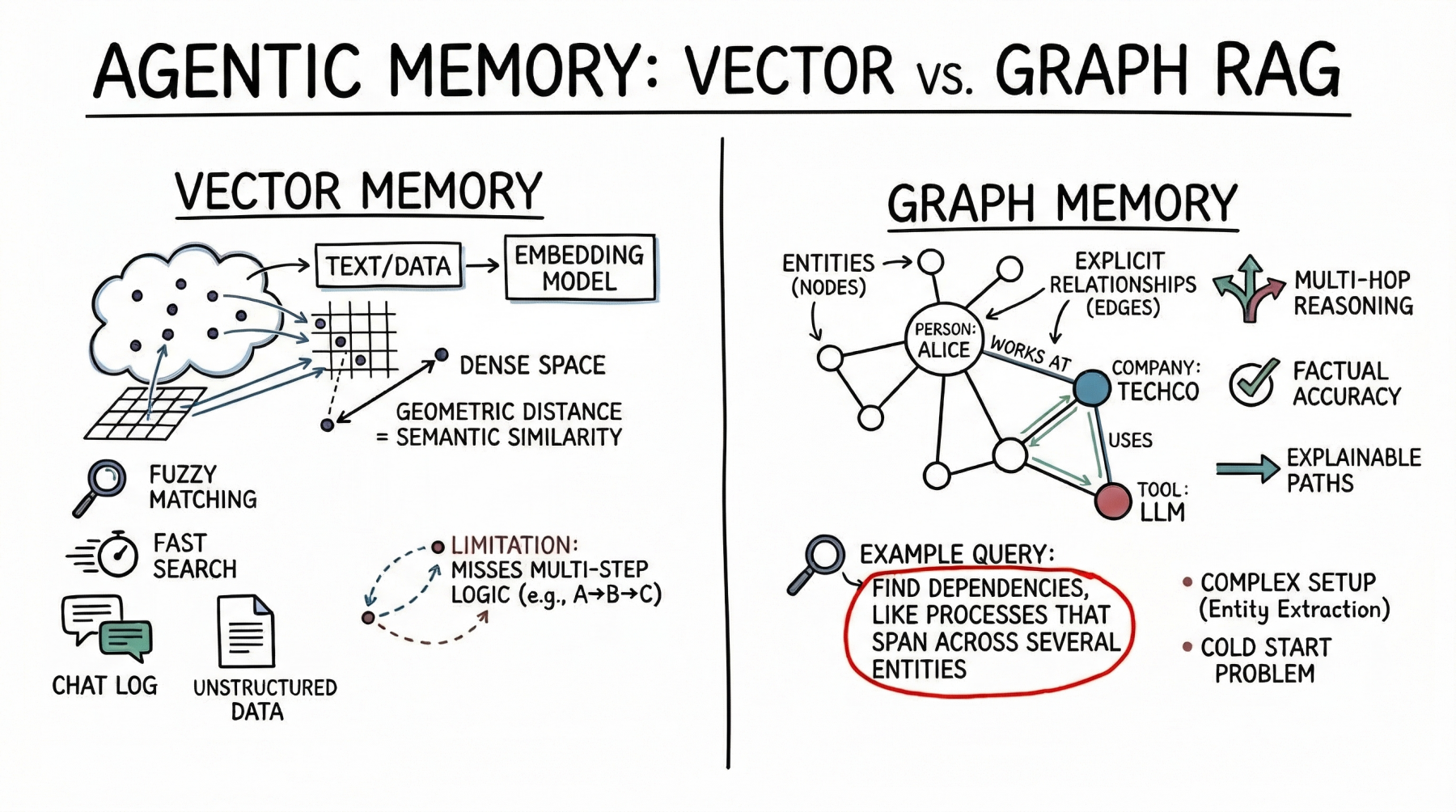
Vector Databases: Fundamentals of Semantic Agent Reminiscence
Vector databases signify reminiscence as dense mathematical vectors, or embeddings, positioned in a high-dimensional house. The embedded mannequin maps textual content, pictures, or different knowledge to an array of floats. Right here, the geometric distance between two vectors corresponds to their semantic similarity.
AI brokers primarily use this strategy to retailer unstructured textual content. A typical use case is storing dialog historical past in order that the agent can keep in mind what the person beforehand requested by looking its reminiscence financial institution for semantically associated previous interactions. The agent additionally leverages the vector retailer to retrieve related documentation, API documentation, or code snippets primarily based on the implicit that means of the person’s immediate. It is a rather more strong strategy than counting on precise key phrase matches.
Vector databases are a viable alternative for agent reminiscence. Quick searches even throughout billions of vectors. Builders may even discover it simpler to arrange than structured databases. To combine vector shops, cut up the textual content, generate embeddings, and index the outcomes. These databases additionally deal with fuzzy matches effectively, coping with typos and paraphrases with out requiring exact queries.
Nevertheless, with semantic search, superior brokers have restricted reminiscence. Vector databases typically can not comply with multi-step logic. For instance, if an agent must discover a hyperlink between entity A and entity C, however solely has knowledge exhibiting that A connects to B and B connects to C, a easy similarity search might miss necessary info.
These databases additionally battle when retrieving giant quantities of textual content or processing noisy outcomes. Dense, interconnected information (from software program dependencies to an organization’s organizational chart) can be utilized to return associated however unrelated info. This will trigger the agent’s context window to turn out to be crowded with much less helpful knowledge.
Graph RAG: Structured Context and Relational Reminiscence
Graph RAG addresses the constraints of semantic search by combining data graphs and LLM. On this paradigm, reminiscences are structured as discrete entities represented as nodes (e.g., folks, firms, applied sciences), and express relationships between them are represented as edges (e.g., “works with” or “makes use of”).
Brokers utilizing graph RAGs create and replace structured fashions of the world. As we gather new info, we extract entities and relationships and add them to the graph. When looking reminiscence, comply with an express path to get the precise context.
The principle power of graph RAG is its accuracy. There’s a decrease danger of error as a result of the search follows express relationships relatively than simply semantic proximity. If a relationship doesn’t exist within the graph, the agent can not infer it from the graph alone.
Graph RAG excels at advanced reasoning and is ideal for answering structured questions. To search out the direct reviews of the supervisor who authorized the finances, comply with the trail via the group and approval chain. Though this can be a easy graph traversal, it’s a troublesome job for vector searches. Ease of clarification can be an enormous benefit. A search path is a transparent and auditable sequence of nodes and edges, relatively than an opaque similarity rating. That is necessary for enterprise purposes that require compliance and transparency.
On the draw back, graph RAGs are considerably extra advanced to implement. Parsing uncooked textual content into nodes and edges requires a strong entity extraction pipeline, typically requiring fastidiously tailor-made prompts, guidelines, or specialised fashions. Builders additionally have to design and keep ontologies or schemas, which may be inflexible and troublesome to evolve when new domains are encountered. Chilly begin points are additionally noticeable. Not like vector databases, that are helpful as quickly as you embed textual content, data graphs require important up-front effort to enter knowledge earlier than answering advanced queries.
Comparability frameworks: when to make use of which one?
When designing reminiscence for AI brokers, take into account that vector databases are higher at dealing with unstructured high-dimensional knowledge and appropriate for similarity searches, whereas graph RAGs are advantageous for representing express relationships when entities and their relationships are necessary. Your alternative ought to be decided by the distinctive construction of your knowledge and anticipated question patterns.
Vector databases are perfect for purely unstructured knowledge, comparable to chat logs, widespread paperwork, or huge data bases constructed from uncooked textual content. That is helpful when the aim of the question is to discover a broad theme, comparable to “Discover ideas much like X” or “What did we focus on concerning matter Y?” From a venture administration perspective, low setup prices and excessive common accuracy make it the default alternative for early stage prototypes and general-purpose assistants.
Conversely, graph RAGs are appropriate for knowledge with uniquely structured or semi-structured relationships, comparable to monetary data, code-based dependencies, and complicated authorized paperwork. It is a good structure when the question requires a exact, categorical reply, comparable to “How precisely is X associated to Y?” or “What are the dependencies of this explicit part?” The setup price and ongoing upkeep overhead of a graph RAG system is justified as a result of it may possibly obtain excessive accuracy on particular connections the place vector search would hallucinate, overgeneralize, or fail.
Nevertheless, the way forward for superior agent reminiscence lies not in selecting between the 2, however in hybrid architectures. An rising variety of main agent techniques mix each strategies. A typical strategy makes use of a vector database for the primary search step and performs a semantic search to seek out essentially the most related entry nodes in a big data graph. As soon as these entry factors are recognized, the system strikes to graph traversal to extract the exact relational context related to these nodes. This hybrid pipeline combines the broad, fuzzy recall of vector embeddings with the strict, deterministic precision of graph traversal.
conclusion
Vector databases stay essentially the most sensible start line for general-purpose agent reminiscence as a result of their ease of deployment and highly effective semantic matching capabilities. Capturing sufficient context is feasible for a lot of purposes, from buyer assist bots to primary coding assistants.
However as we goal to realize autonomous brokers able to enterprise-grade workflows, comprised of brokers that have to purpose about advanced dependencies, guarantee factual accuracy, and clarify logic, graph RAGs are rising as a key unlocker.
We suggest that builders take a layered strategy. Begin the agent’s reminiscence with a vector database as the idea for primary conversations. Because the agent’s reasoning necessities develop and we strategy the sensible limits of semantic search, we selectively deploy data graphs to construction high-value entities and core operational relationships.


