




The “uncanny valley” is the ultimate frontier of generative video. We’ve got seen AI avatars that may discuss, however they usually lack the soul of human interplay. They endure from stiff actions and an absence of emotional context. Tavus goals to unravel this drawback with the discharge of Phoenix-4, a brand new generative AI mannequin designed for conversational video interfaces (CVI).
Phoenix-4 represents a transition from static video technology to dynamic, real-time human rendering. It isn’t nearly shifting your lips. It is about creating digital people that acknowledge, time, and react with emotional intelligence.
Three powers: Raven, Sparrow, Phoenix
To attain true realism, Tavus makes use of a three-part mannequin structure. Understanding how these fashions work together is essential for builders trying to construct conversational brokers.
Raven-1 (Notion): This mannequin acts because the “eyes and ears”. Analyze customers’ facial expressions and tone of voice to know the emotional context of conversations. Sparrow-1 (Timing): This mannequin manages the movement of the dialog. The AI decides when to interrupt, pause, or look forward to the consumer to complete, making interactions really feel pure. Phoenix-4 (rendering): Core rendering engine. Synthesize photorealistic movies in actual time utilizing Gaussian diffusion.
Technical breakthrough: Gaussian diffusion rendering
Phoenix-4 departs from conventional GAN-based approaches. As an alternative, it makes use of a proprietary Gaussian diffusion rendering mannequin. This enables AI to calculate advanced facial actions, such because the impact of pores and skin stretch on gentle and minute facial expressions across the eyes.
Which means the mannequin can deal with spatial consistency higher than earlier variations. Textures and lighting stay steady even when the digital human turns his or her head. This mannequin produces these high-fidelity frames at a price that helps 30 frames per second (fps) streaming, which is crucial to sustaining the phantasm of life.
Breaking by the latency barrier: lower than 600ms
At CVI, velocity is every little thing. If the time between the consumer talking and the AI responding is simply too lengthy, the “human” really feel is misplaced. Tavus has developed a Phoenix 4 pipeline that achieves end-to-end dialog latency of lower than 600ms.
That is achieved by a “stream-first” structure. This mannequin makes use of WebRTC (Net Actual-Time Communication) to stream video information on to the consumer’s browser. Phoenix-4 renders and sends video packets in levels, fairly than producing and taking part in full video recordsdata. This retains the time to first body to an absolute minimal.
Programmatic emotion management
Probably the most highly effective options is the Emotion Management API. Builders can now explicitly outline the emotional state of a persona throughout a dialog.
You possibly can set off particular behavioral outputs by passing emotion parameters in your API requests. The mannequin presently helps the next main emotional states:
pleasure unhappiness anger shock
When the emotion is about to Pleasure, the Phoenix-4 engine adjusts the form of the face to create a real smile, affecting not solely the mouth but additionally the cheeks and eyes. It is a type of conditional video technology the place the output is influenced by each text-to-speech phonemes and emotion vectors.
Constructing with replicas
Making a customized “duplicate” (digital twin) requires solely two minutes of coaching video footage. As soon as coaching is full, you may deploy your duplicate by the Tavus CVI SDK.
The workflow is easy.
Practice: Create a singular replica_id by importing a 2-minute video of somebody talking. Deploy: Begin a session utilizing the POST /conversations endpoint. Settings: Set persona_id and conversation_name. Join: Hyperlink the supplied WebRTC URL to your frontend video part.
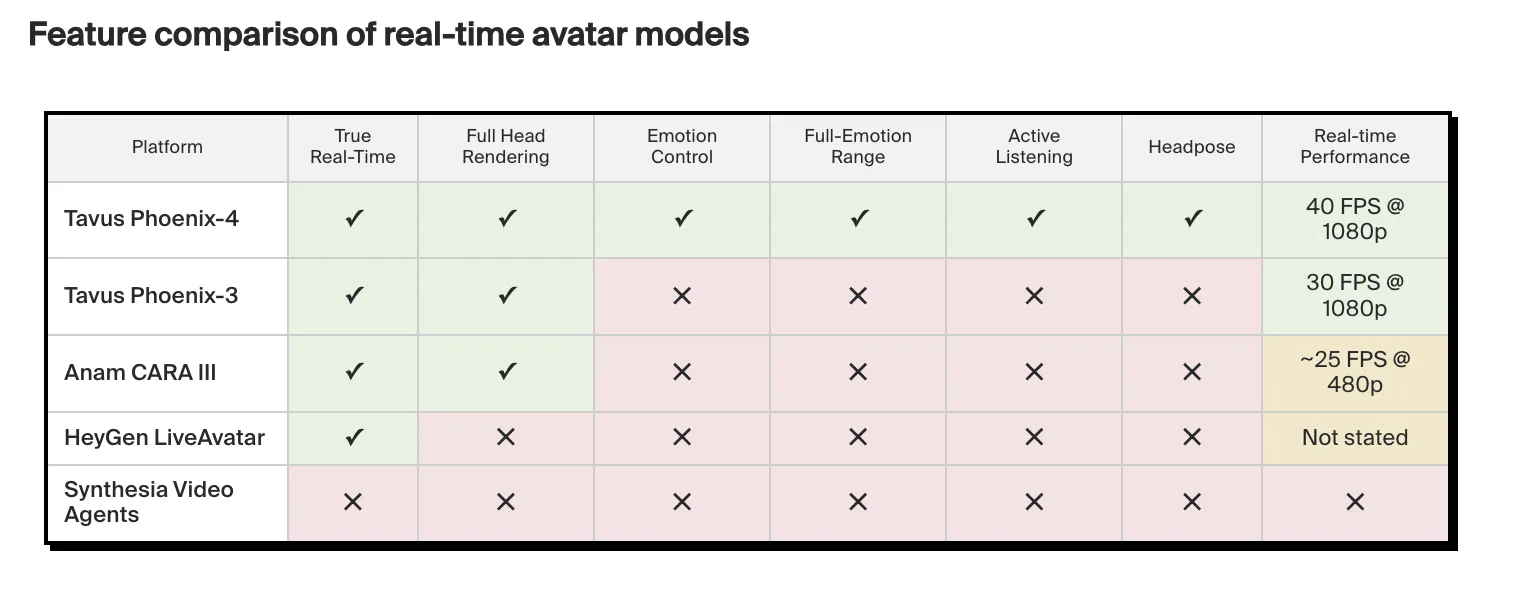
Essential factors
Gaussian Diffusion Rendering: Phoenix-4 goes past conventional GANs to make use of Gaussian Diffusion to allow high-fidelity, photorealistic facial actions and delicate expressions that clear up the “Uncanny Valley” drawback. AI Trinity (Raven, Sparrow, Phoenix): This structure depends on three completely different fashions. Raven-1 is emotion recognition, Sparrow-1 is dialog timing/turn-taking, and Phoenix-4 is closing video compositing. Extremely-low latency: Optimized for conversational video interfaces (CVI), this mannequin leverages WebRTC to stream video packets in real-time, attaining end-to-end latency of lower than 600ms. Programmatic emotion management: Use the emotion management API to dynamically alter the form and expression of your character’s face, specifying states akin to pleasure, unhappiness, anger, and shock. Fast Duplicate Coaching: Making a customized digital twin (“duplicate”) is extremely environment friendly, requiring solely 2 minutes of video footage to coach a singular ID for deployment by way of the Tavus SDK.
Take a look at the technical particulars, documentation, and check out it out right here. Additionally, be at liberty to observe us on Twitter. Additionally, do not forget to hitch the 100,000+ ML SubReddit and subscribe to our e-newsletter. dangle on! Are you on telegram? Now you can additionally take part by telegram.


