




How to Combine LLM Embeddings + TF-IDF + Metadata in One Scikit-learn Pipeline
On this article, you'll learn to fuse dense LLM sentence embeddings, sparse…
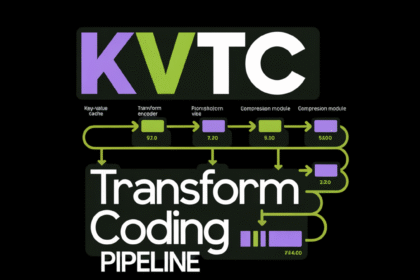
NVIDIA Researchers Introduce KVTC Transform Coding Pipeline to Compress Key-Value Caches by 20x for Efficient LLM Serving
Offering massive language fashions (LLMs) at scale is a significant engineering problem…
