




How to Combine LLM Embeddings + TF-IDF + Metadata in One Scikit-learn Pipeline
On this article, you'll learn to fuse dense LLM sentence embeddings, sparse…

Fast Local LLM Inference, Hardware Choices & Tuning
Native giant‑language‑mannequin (LLM) inference has grow to be one of the crucial…
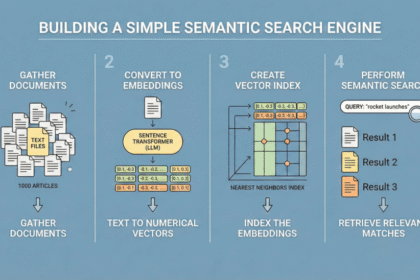
Build Semantic Search with LLM Embeddings
On this article, you'll discover ways to construct a easy semantic search…
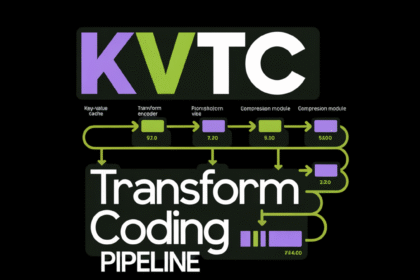
NVIDIA Researchers Introduce KVTC Transform Coding Pipeline to Compress Key-Value Caches by 20x for Efficient LLM Serving
Offering massive language fashions (LLMs) at scale is a significant engineering problem…

AI Strategy After the LLM Boom: Maintain Sovereignty, Avoid Capture
It’s time to rethink your AI publicity, deployment, and technique This week,…

How to Design a Fully Streaming Voice Agent with End-to-End Latency Budgets, Incremental ASR, LLM Streaming, and Real-Time TTS
On this tutorial, you'll construct an end-to-end streaming voice agent that mirrors…

15 Free LLM APIs You Can Use in 2026
If you're trying to find free LLM APIs, likelihood is you already need…

Why “which API do I call?” is the wrong question in the LLM era
Over the a long time, we now have tailored to software program.…

Prompt Compression for LLM Generation Optimization and Cost Reduction
On this article, you'll be taught 5 sensible immediate compression strategies that…
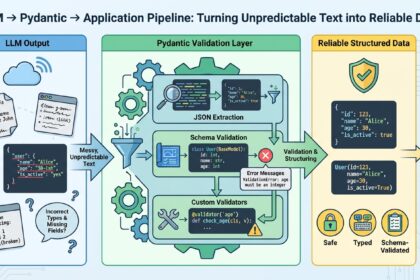
The Complete Guide to Using Pydantic for Validating LLM Outputs
On this article, you'll discover ways to flip free-form massive language mannequin…
