




Why deal with LLM inference as a batch kernel to drums when the dataflow compiler can pipe tiles by on-chip FIFOS and stream converters? Stream Tenser is a compiler that reduces Pytorch LLM graphs (GPT-2, LLAMA, QWEN, GEMMA) and is an information movement accelerator that flows to AMD’s Alveo U5ca Schellow Eccelerators. The system introduces an iterative tensor (“Itensor”) sort for encoding Tile/Order of Streams, permitting it to show automated insertion/sizing of DMA engines, FIFOs, and format converters. For LLM decoding workloads, the analysis group reviews as much as 0.64 x low latency vs. GPU and as much as 1.99 instances power effectivity.
What’s a stream tenser?
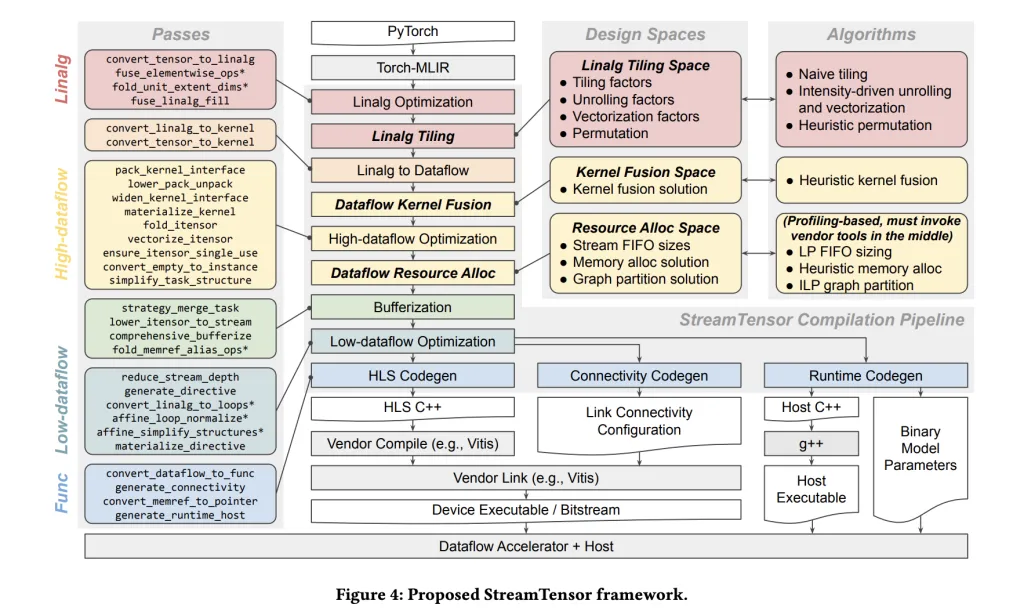
StreamTensor compiles Pytorch graphs into stream-oriented dataflow designs, with intermediate tiles nearly avoiding off-chip drum spherical journeys through on-chip streaming and fusion. The DMA is inserted solely when mandatory. They’re transferred to the downstream kernel through on-chip FIFOs. Compiler heart abstraction – Utilized tensors – information iterative order, tiles, format. This framework hierarchically searches tiles, fusions, and useful resource allocations, and makes use of linear applications to dimension FIFOS to keep away from meals stalls and deadlocks whereas minimizing on-chip reminiscence.
What’s actually new?
Layer DSE. The compiler investigates three design areas: (i) tile/untilization/vectorization/permutation on the Linux stage, (ii) fusion underneath reminiscence/useful resource constraints, and (iii) Optimizing sustained throughput underneath bandwidth limits. Finish-to-end Pytorch → Machine Circulate. The mannequin is enter through Torch-Mlir and transformed to Mlir Linelg, then transformed to a dataflow IR the place the node turns into a {hardware} kernel with express streams and host/runtime adhesives. There isn’t a handbook RTL meeting. Iterative tensor typing system. Top notch tensor varieties characterize iterative order, tiles, and affine maps. This enables for express stream ordering, permitting safe kernel fusion, and permits the compiler to synthesize minimal buffer/format converters if the producer/shopper disagrees. Official FIFO sizing. It’s resolved by linear programming formulations to keep away from stall/deadlocks whereas minimizing on-chip reminiscence utilization (BRAM/URAM).
outcome
Latency: As much as 0.76×× vs. GPU baseline on the earlier FPGA LLM accelerator and 0.64×vs. Vitality Effectivity: As much as 1.99 x VS A100 (mannequin dependent) with the brand new LLMS. Platform context: ALVEO U55C (HBM2 16 GB, 460 GB/s, PCIE GEN3x16 or Twin GEN4x8, 2xQSFP28).
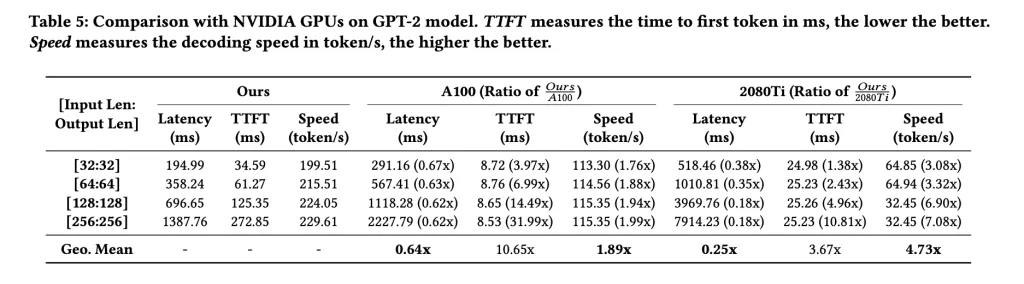
A helpful contribution right here is the Pytorch→Torch-Mlir→Dataflow compiler, which emits the host/runtime of AMD’s ALVEO U55C. Iterative tensor varieties and linear programming-based FIFO sizing enable for protected inter-kernel streaming fairly than drum spherical journeys. Within the reported LLM decoding benchmarks for GPT-2, Llama, Qwen, and Gemma, the analysis group reveals GPU baselines and low energy-efficient geometric imply latency with GPU baselines as much as 1.99×. The {hardware} context is obvious. The ALVEOU55C presents twin QSFP28 at 460 GB/s and 16 GB HBM2 at 460 GB/s with PCIE GEN3x16 or twin GEN4x8 at 460 GB/s.
Take a look at the paper. For tutorials, code and notebooks, please go to our GitHub web page. Additionally, be at liberty to observe us on Twitter. Do not forget to hitch 100K+ ML SubredDit and subscribe to our publication.

Mikal Sutter is an information science skilled with a Grasp’s diploma in Information Science from Padova College. With its stable foundations of statistical evaluation, machine studying, and information engineering, Michal excels at reworking complicated datasets into actionable insights.
Comply with marktechpost: Add as Google’s most well-liked supply.


