




ROC AUC vs Precision-Recall for Unbalanced Information
Photos by editor | chatgpt
introduction
Machine studying fashions for classifying unbalanced knowledge, i.e. datasets with far much less presence of 1 class (e.g. spam electronic mail) than the presence of one other class (e.g. non-spam electronic mail) – sure conventional metrics comparable to accuracy and ROC AUC (receiving the working attribute curve and the areas beneath) present lifelike efficiency.
Alternatively, the Precision-Recall curve (or PR curve for brief) is designed to focus particularly on constructive, normally extra uncommon lessons, that are way more helpful measures of datasets distorted because of class imbalances.
Via dialogue and three sensible situations, this text offers a comparability of ROC AUC and PRAUC for the areas below each curves (values from 0 to 1) throughout three imbalanced datasets, by coaching and evaluating a easy classifier primarily based on logistic regression.
ROC AUC vs Precision-Recall
The ROC curve is a go-to method to assessing the flexibility of classifiers to tell apart between lessons. That’s, by plotting the TPR (true constructive charge) towards FPR (false constructive charge) towards completely different thresholds as a result of likelihood of belonging to a constructive class. In the meantime, the Precision-Recall (PR) curve plots accuracy for various threshold remembers and focuses on analyzing the efficiency of constructive class predictions. Subsequently, it’s notably helpful and useful for comprehensively assessing classifiers educated on unbalanced datasets. Alternatively, ROC curves usually are not delicate to class imbalances and are appropriate for evaluating classifiers constructed on pretty balanced datasets.
Briefly, going again to the PR curve and sophistication imbalance dataset, excessive stakes situations that accurately establish constructive class situations are necessary (e.g., figuring out the presence of a affected person’s illness), and the PR curve is a extra dependable measure of classifier efficiency.
Extra visually, if each curves are plotted towards one another, we have to get hold of a rise within the case of ROC and a lower within the case of PR. The nearer the ROC curve is to (0,1) factors, the higher it means one of the best TPR and lowest FPR. When the PR curve approaches (1,1) factors, it implies that each accuracy and recall are at most, however it’s higher. At each bases, approaching these “full mannequin factors” implies that the area below the curve or AUC can be maximized. That is the quantity you’ll search for within the instance beneath.
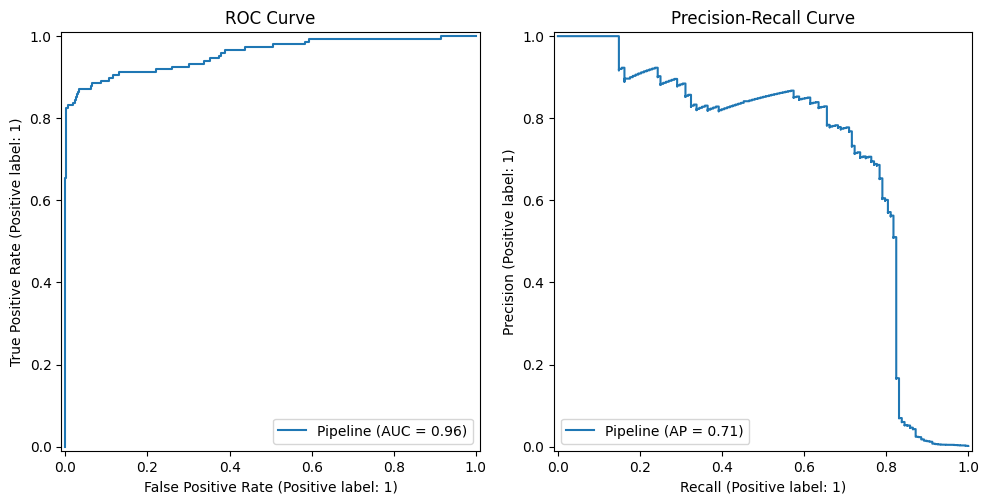
Examples of ROC curves and precision restoration curves
Photos by the creator
For instance the use and comparability of ROC AUC and Precision-Recall (PR curves for brief), we think about three datasets with completely different ranges of sophistication imbalance. First, import every thing you want for all three examples.
Import PANDAS as PD from sklearn.Datasets load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.linear_model sklearn.preprocessing Import Standardscaler from sklearn.pipeline intermedcaLine from Import Import Import Sort Average_precision_score
Import Panda As PD
from Sklearn.Dataset Import load_breast_cancer
from Sklearn.Model_Selection Import train_test_split
from Sklearn.linear_model Import Logiss Recussion
from Sklearn.Pre-processing Import StandardScaler
from Sklearn.Pipeline Import make_pipeline
from Sklearn.metric Import ROC_AUC_SCORE, Average_precision_score
Instance 1: Gentle imbalances between curves and completely different efficiency
The Pima Indians diabetes knowledge set is barely unbalanced. Roughly 35% of sufferers are recognized with diabetes (class label equal to 1), whereas the opposite 65% have a detrimental diabetes prognosis (class label equal to 0).
This code hundreds the information, prepares it, trains a binary classifier primarily based on logistic regression, and calculates the area below two sorts of curves which can be described.
# Get knowledge cols = [“preg”,”glucose”,”bp”,”skin”,”insulin”,”bmi”,”pedigree”,”age”,”class”]df = pd.read_csv (“https://uncooked.githubusercontent.com/jbrownlee/datasets/grasp/pima-indians-diabetes.knowledge.csv”, names = cols)[“class”]x_train, x_test, y_train, y_test = train_test_split(x, y, stratify = y, test_size = 0.3, random_state = 42) Precision-Recall auc probs = clf.predict_proba(x_test)[:,1]print(“roc auc:”, roc_auc_score(y_test, probs)) print(“pr auc:”, verage_precision_score(y_test, probs)))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
twenty one
#Get knowledge
cols = [“preg”,“glucose”,“bp”,“skin”,“insulin”,“bmi”,“pedigree”,“age”,“class”]
DF = PD.read_csv(“https://uncooked.githubusercontent.com/jbrownlee/datasets/grasp/pima-indians-diabetes.knowledge.csv”,
title=cols))
# Separate the labels and break up them into coaching assessments
x, y = DF.Drop it(“class”, shaft=1)), DF[“class”]
x_train, x_test, y_train, y_test = train_test_split(
x, y, Stratification=y, test_size=0.3, random_state=42
))
#Scale knowledge and coaching classifiers
clf = make_pipeline(
StandardScaler()),
Logiss Recussion(max_iter=1000))
)).match(x_train, y_train))
# Get ROC AUC and Precision-Recall AUC
downside = clf.predict_proba(x_test))[:,1]
printing(“Roc Auc:”, ROC_AUC_SCORE(y_test, downside))))
printing(“Pr AUC:”, Average_precision_score(y_test, downside))))
On this case I bought a ROC-AUC equal to about 0.838 and a PR-AUC of 0.733. As we are able to observe, PRAUC (Precision-Recall) is reasonably decrease than ROC AUC, as ROC AUC tends to overestimate the classification efficiency of unbalanced datasets. This can be a frequent sample in lots of datasets. The next instance makes use of an equally unbalanced dataset with completely different outcomes:
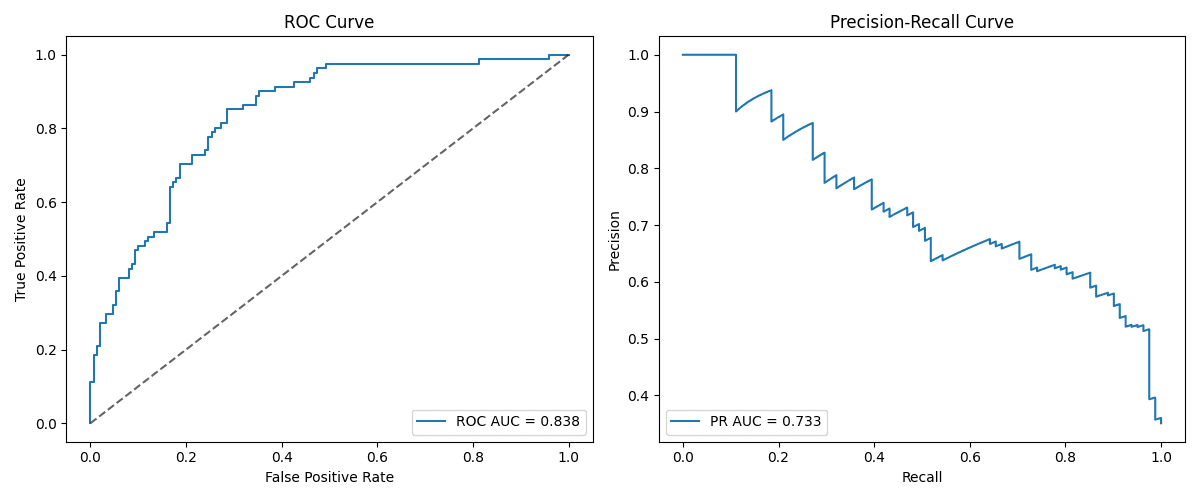
Photos by the editor
Instance 2: Gentle imbalances between curves and comparable efficiency
One other unbalanced dataset with a category share that’s pretty just like the earlier class share is the Wisconsin breast most cancers dataset out there in Scikit-Be taught, with 37% of the situations being constructive.
Apply the same course of to the earlier instance of the brand new dataset and analyze the outcomes.
knowledge=load_breast_cancer() x, y=knowledge.knowledge, (knowledge.goal== 1).astype(int) x_train, x_test, y_train, y_test=train_test_split(x, y, y, stratify=y, test_size=0.3, random_state=42) clf=make_pipeler() logististression(max_iter=1000)).match(x_train, y_train)probs=clf.predict_proba(x_test)[:,1]print(“roc auc:”, roc_auc_score(y_test, probs)) print(“pr auc:”, verage_precision_score(y_test, probs)))
knowledge = load_breast_cancer())
x, y = knowledge.knowledge, (knowledge.goal==1)).ASTYPE(int))
x_train, x_test, y_train, y_test = train_test_split(
x, y, Stratification=y, test_size=0.3, random_state=42
))
clf = make_pipeline(
StandardScaler()),
Logiss Recussion(max_iter=1000))
)).match(x_train, y_train))
downside = clf.predict_proba(x_test))[:,1]
printing(“Roc Auc:”, ROC_AUC_SCORE(y_test, downside))))
printing(“Pr AUC:”, Average_precision_score(y_test, downside))))
On this case, there’s a ROC AUC of 0.9981016355140186 and a PRAUC of 0.9988072626510498. That is an instance that demonstrates that metric-specific mannequin efficiency usually relies upon not solely on class imbalances, but additionally on a mixture of many components. Class imbalances can typically replicate variations between PR vs. ROC AUC, however dataset traits comparable to measurement, complexity, and sign power from attributes are additionally influential. This explicit dataset produced a classifier that was typically pretty performant. This may increasingly partially clarify its robustness to class imbalances (contemplating the excessive PRAUC obtained).
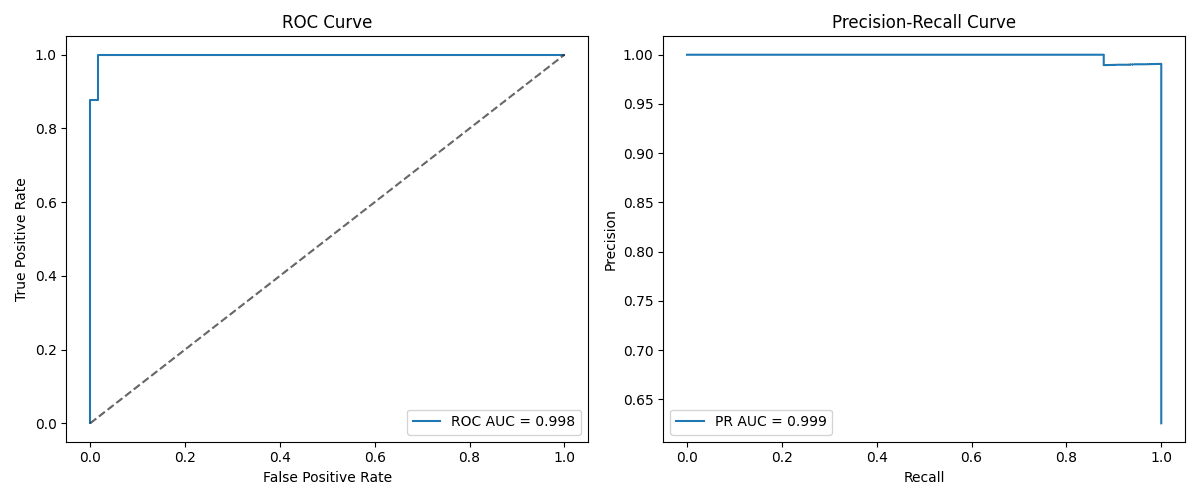
Photos by the editor
Instance 3: Excessive imbalance
The final instance makes use of a really unbalanced dataset: a bank card fraud detection dataset. On this dataset, lower than 1% of practically 285k situations belong to the constructive class, indicating transactions labeled as fraud.
url = “https://uncooked.githubusercontent.com/nsethi31/kaggle-data-credit-card-fraud-section/grasp/creditcard.csv” df = pd.read_csv(url)x, y = df.drop( “class = 1), df), df[“Class”]x_train, x_test, y_train, y_test = train_test_split(x, y, y, stratify = y, test_size = 0.3, random_state = 42) clf = make_pipeline(), logisticrestression(), logisticrestression(max_iter = 2000)).match(x_train, y_train = probs prob clf.predict_proba(x_test)[:,1]print(“roc auc:”, roc_auc_score(y_test, probs)) print(“pr auc:”, verage_precision_score(y_test, probs)))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
URL = ‘https://uncooked.githubusercontent.com/nsethi31/kaggle-data-credit-card-fraud-section/grasp/creditcard.csv’
DF = PD.read_csv(URL))
x, y = DF.Drop it(“class”, shaft=1)), DF[“Class”]
x_train, x_test, y_train, y_test = train_test_split(
x, y, Stratification=y, test_size=0.3, random_state=42
))
clf = make_pipeline(
StandardScaler()),
Logiss Recussion(max_iter=2000))
)).match(x_train, y_train))
downside = clf.predict_proba(x_test))[:,1]
printing(“Roc Auc:”, ROC_AUC_SCORE(y_test, downside))))
printing(“Pr AUC:”, Average_precision_score(y_test, downside))))
This instance clearly exhibits that it normally happens in extremely unbalanced knowledge units. The acquired PRAUCs with ROC AUCs of 0.957 and 0.708 have a powerful overestimation of mannequin efficiency as a result of ROC curve. Because of this whereas ROC seems to be very promising, in actuality, it’s uncommon, and due to this fact the constructive circumstances usually are not correctly captured. A frequent sample is that the stronger the imbalance, the better the distinction between ROC AUC and PRAUC.
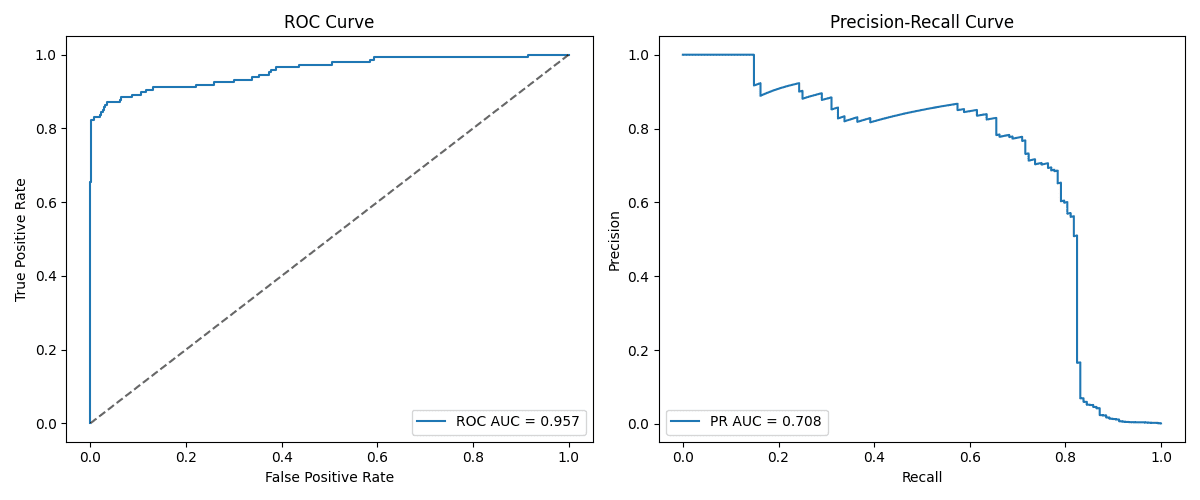
Photos by the editor
I am going to summarize
On this article, we are going to clarify and examine two frequent metrics to evaluate the efficiency of the classifier. ROC and Precision-Recall Curves. Via three examples of unbalanced datasets, we demonstrated the conduct and really helpful use of those metrics in varied situations. A standard necessary lesson is that precision recall curves are typically a extra helpful and lifelike technique to assess classifiers in school absorption knowledge.
Learn extra about find out how to navigate imbalanced datasets for classification. Please see this text.


