



Alibaba Cloud’s Qwen staff has open-sourced Qwen3-TTS, a household of multilingual text-to-speech fashions that targets three core duties in a single stack: voice cloning, voice design, and high-quality voice technology.
Mannequin household and options
Qwen3-TTS makes use of a 12Hz speech tokenizer and two language mannequin sizes (0.6B and 1.7B), packaged into three principal duties. The open launch contains Qwen3-TTS-12Hz-0.6B-Base and Qwen3-TTS-12Hz-1.7B-Base for voice clones and generic TTS, Qwen3-TTS-12Hz-0.6B-CustomVoice and Qwen3-TTS-12Hz-1.7B-CustomVoice for promptable preset audio system. Two fashions have been printed. Qwen3-TTS-12Hz-1.7B-VoiceDesign, together with the Qwen3-TTS-Tokenizer-12Hz codec, creates free-form speech from pure language descriptions.
All fashions help 10 languages: Chinese language, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian. CustomVoice variants include 9 fastidiously chosen tones, together with Vivian, a cheerful younger Chinese language feminine voice, Ryan, a dynamic male English voice, and Ono_Anna, a playful Japanese feminine voice, every with a brief description that encodes the tone and talking type.
The VoiceDesign mannequin maps textual content directions on to new voices. For instance, “Communicate within the voice of a nervous male teenager, with a rising intonation.” You may mix it with the Base mannequin by first producing a brief reference clip and reusing it with create_voice_clone_prompt.
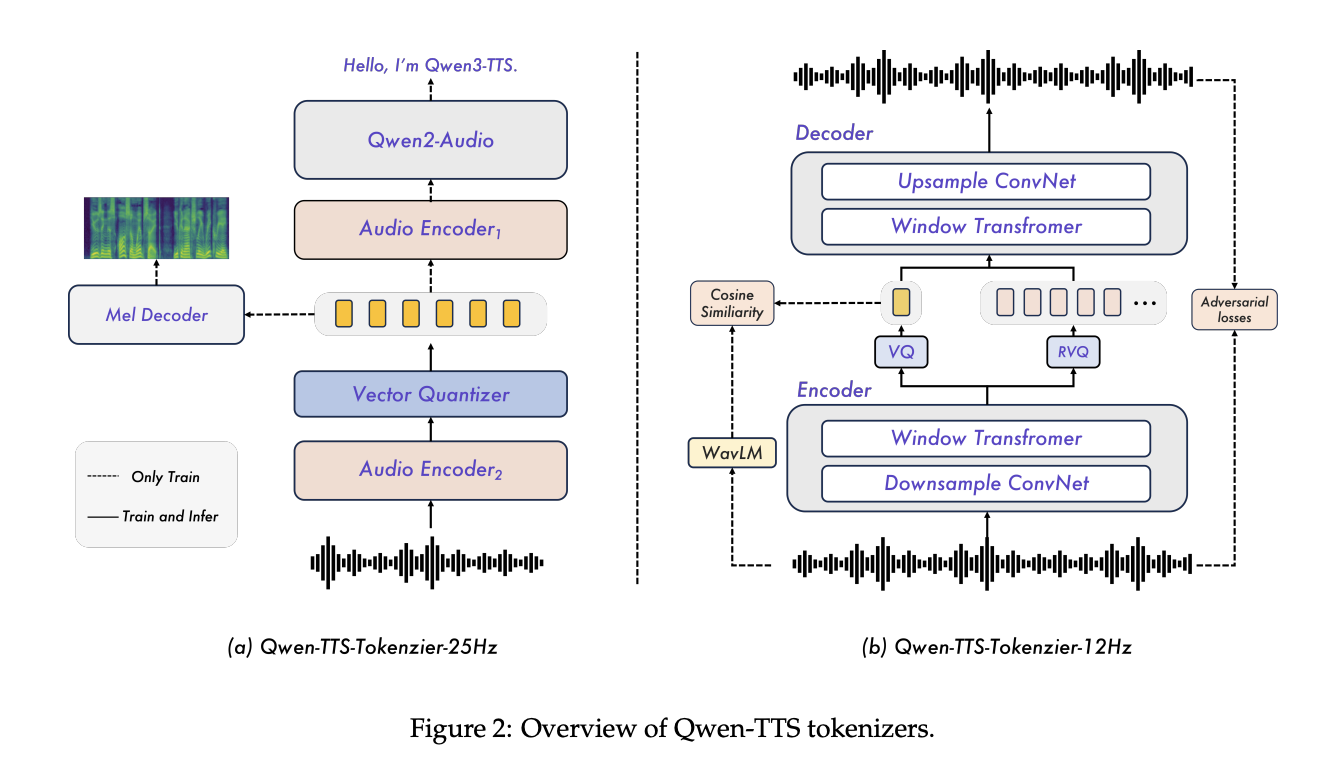
Structure, tokenizers, streaming paths
Qwen3-TTS is a dual-track language mannequin, the place one monitor predicts discrete acoustic tokens from textual content and the opposite monitor handles alignment and management alerts. The system is skilled on over 5 million hours of multilingual audio, with three pre-training phases that transfer from normal mapping to high-quality information and help for longer contexts as much as 32,768 tokens.
The important thing element is the Qwen3-TTS-Tokenizer-12Hz codec. It operates at 12.5 frames per second, roughly 80 ms per token, and makes use of 16 quantizers with a 2048 entry codebook. Within the LibriSpeech take a look at clear, it reaches PESQ Wideband 3.21, STOI 0.96, and UTMOS 4.16, outperforming SpeechTokenizer, XCodec, Mimi, FireredTTS 2, and different current semantic tokenizers whereas utilizing comparable or decrease body charges.
The tokenizer is carried out as a pure left-context streaming decoder, so it might output the waveform as quickly as sufficient tokens can be found. With 4 tokens per packet, every streaming packet carries 320ms of audio. Non-DiT decoder and BigVGAN-free design scale back decoding price and simplify batch processing.
On the language mannequin facet, the analysis staff experiences end-to-end streaming measurements on a single vLLM backend utilizing torch.compile and CUDA Graph optimizations. For Qwen3-TTS-12Hz-0.6B-Base and Qwen3-TTS-12Hz-1.7B-Base with concurrency of 1, the primary packet delay is roughly 97 ms and 101 ms, and the real-time issue is 0.288 and 0.313, respectively. Even with concurrency of 6, the primary packet delay stays at roughly 299 and 333 ms.
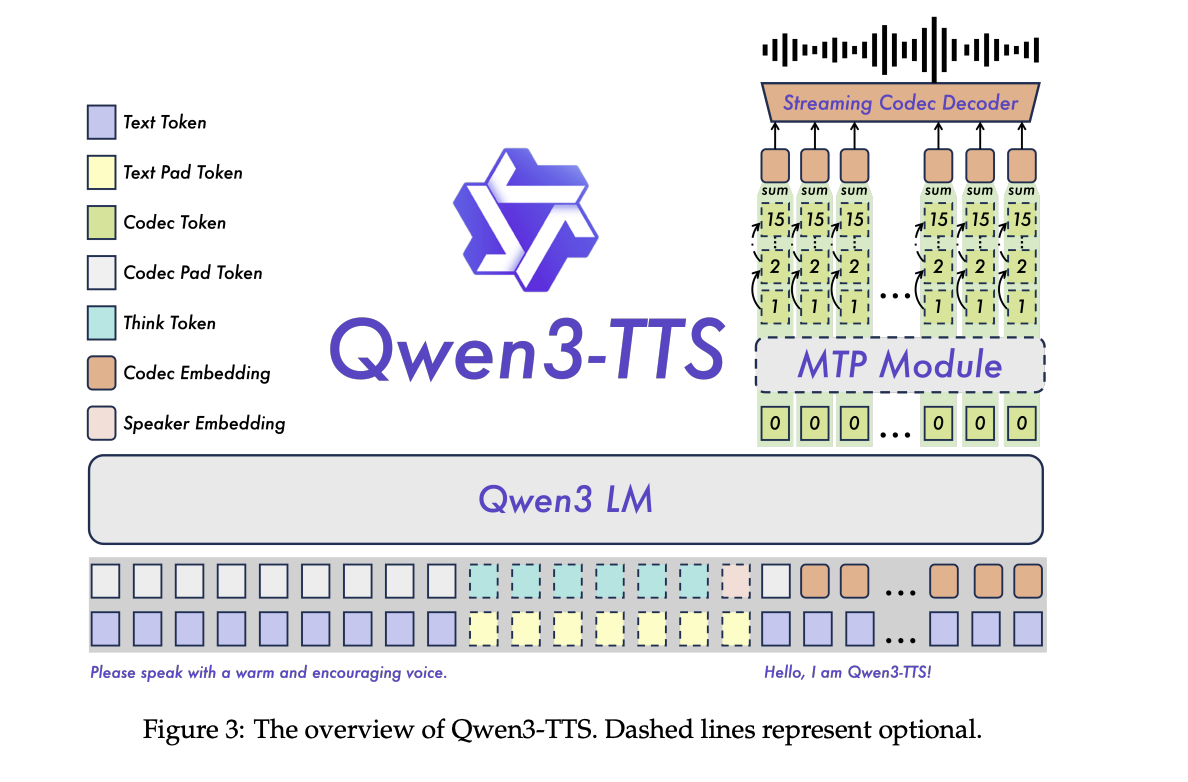
alignment and management
Put up-training makes use of a step-by-step tuning pipeline. First, direct choice optimization aligns the generated speech to human preferences for multilingual information. Second, GSPO with rule-based rewards improves stability and prosody. The ultimate speaker fine-tuning stage of the bottom mannequin yields the focused speaker variant whereas retaining the core performance of the generic mannequin.
Following directions is carried out within the type of ChatML kinds, the place textual content directions relating to type, emotion, or tempo are prepended to the enter. This identical interface powers VoiceDesign, CustomVoice type prompts, and fine-grained enhancing of cloned audio system.
Benchmarking, zero-shot cloning, and multilingual speech
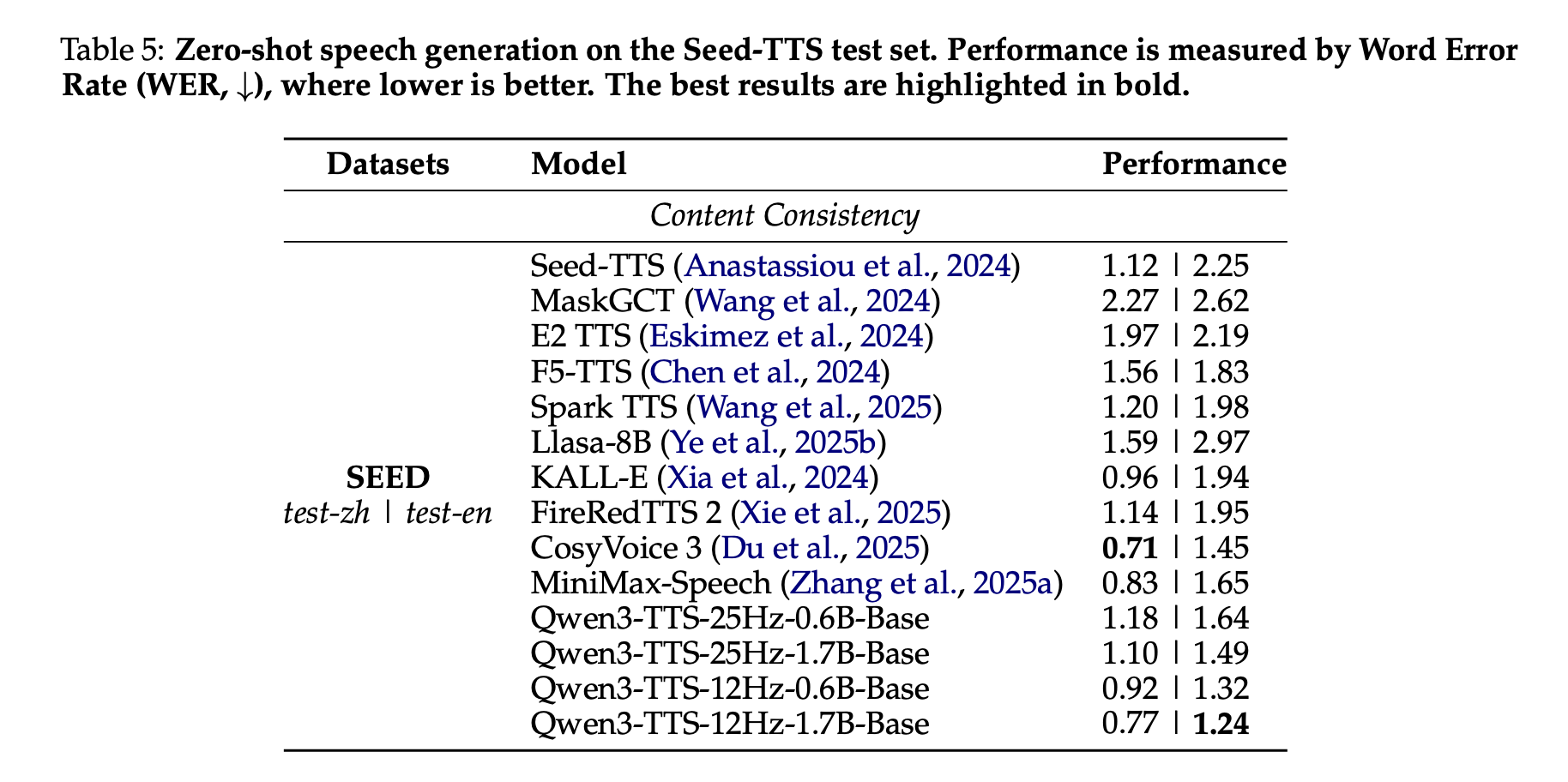
Within the Seed-TTS take a look at set, Qwen3-TTS is evaluated as a zero-shot voice cloning system. The phrase error price of Qwen3-TTS-12Hz-1.7B-Base mannequin reaches 0.77 for test-zh and 1.24 for test-en. The analysis staff emphasizes that test-en’s 1.24 WER is state-of-the-art among the many methods in contrast, whereas China’s WER is near, however not decrease than, CosyVoice 3’s highest rating.
On a multilingual TTS take a look at set masking 10 languages, Qwen3-TTS achieved the bottom WER in 6 languages: Chinese language, English, Italian, French, Korean, and Russian, comparable efficiency within the remaining 4 languages, and the best speaker similarity in all 10 languages in comparison with MiniMax-Speech and Celebrities Multilingual v2.
Cross-language analysis reveals that Qwen3-TTS-12Hz-1.7B-Base reduces the blending error price for some language pairs similar to zh-to-ko, with errors dropping from 14.4 for CosyVoice3 to 4.82, a relative discount of about 66%.
In InstructTTSEval, the Qwen3TTS-12Hz-1.7B-VD VoiceDesign mannequin scores state-of-the-art amongst open-source fashions for rationalization and speech consistency and response accuracy in each Chinese language and English, and competes with business methods similar to Hume and Gemini on a number of metrics.
Essential factors
Full open-source multilingual TTS stack: Qwen3-TTS is an Apache 2.0 licensed suite that covers three duties in a single stack, high-quality TTS, 3-second voice cloning, and instruction-based voice design throughout 10 languages utilizing the 12Hz tokenizer household. Environment friendly discrete codec and real-time streaming: Qwen3-TTS-Tokenizer-12Hz makes use of 16 codebooks at 12.5 frames/second and reaches robust PESQ, STOI, and UTMOS scores, with roughly 320 ms of audio and 120 ms per packet on 0.6B and 1.7B fashions in reported setups. Helps packetized streaming with sub-millisecond first packet delay. Job-specific mannequin variants: This launch offers a Base mannequin for cloning and general-purpose TTS, a CustomVoice mannequin with 9 predefined audio system and magnificence prompts, and a VoiceDesign mannequin that generates new voices straight from pure language descriptions that may be reused within the Base mannequin. Highly effective alignment and multilingual high quality: With a multi-stage alignment pipeline with DPO, GSPO, and speaker fine-tuning, Qwen3-TTS achieves low phrase error charges and excessive speaker similarity, with the bottom WER in 6 out of 10 languages and the best speaker similarity in all 10 languages among the many evaluated methods, making a state-of-the-art zero-shot English clone in Seed TTS.
Test your mannequin weights, repositories, and playgrounds. Additionally, be at liberty to comply with us on Twitter. Additionally, do not forget to hitch the 100,000+ ML SubReddit and subscribe to our publication. cling on! Are you on telegram? Now you can additionally take part by telegram.


