



The OpenAI group has launched the openai/circuit-sparsity mannequin to Hugging Face and the openai/circuit_sparsity toolkit to GitHub. This launch packages the mannequin and circuit from the paper “Weight-sparse transformers have interptable Circuit”.
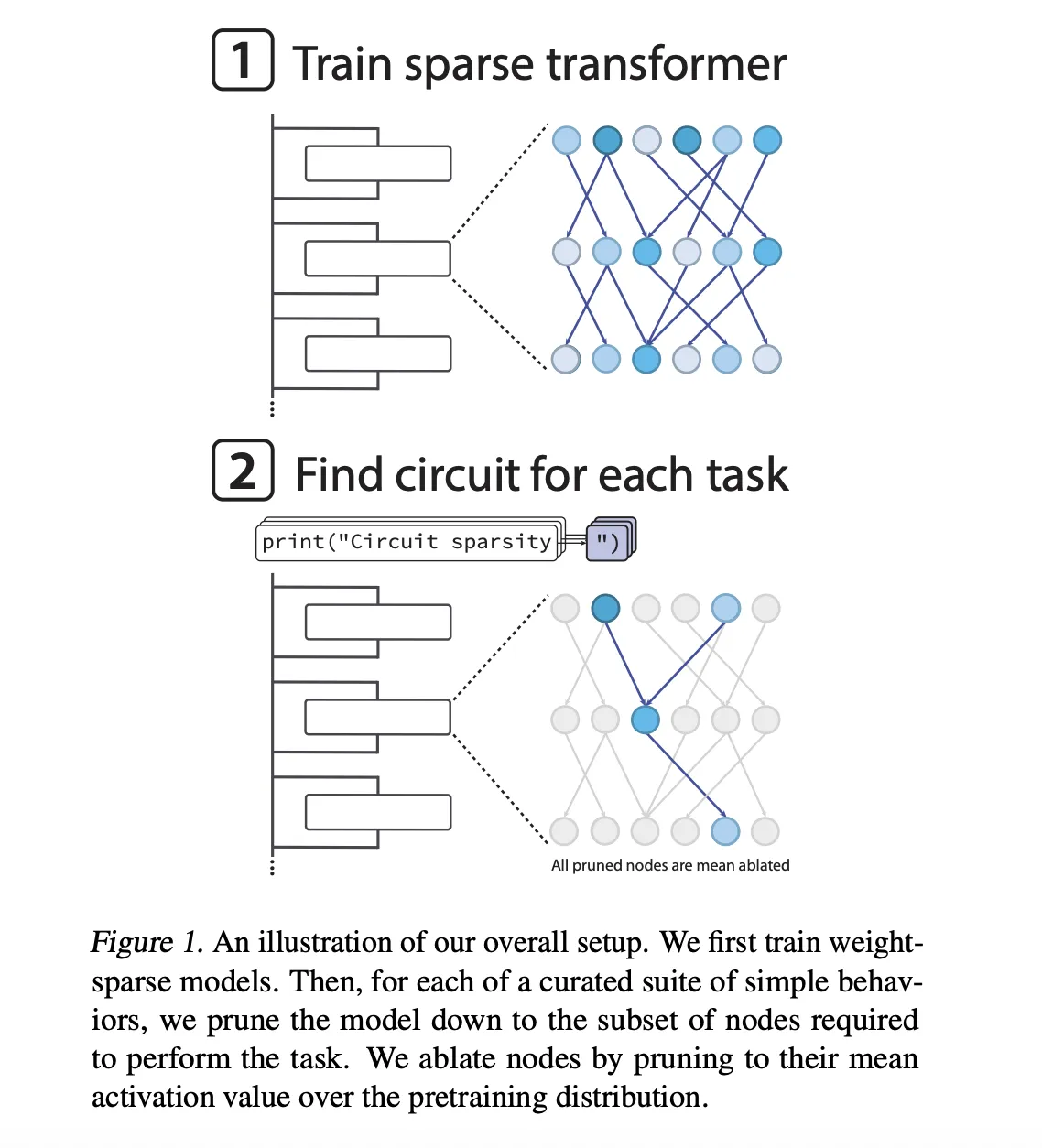
What’s a weight sparse transformer?
The mannequin is a GPT-2 model decoder-only transformer skilled with Python code. Sparsity is utilized throughout optimization fairly than being added after coaching. After every step of AdamW, the coaching loop solely retains the biggest magnitude entry of all weight matrices and biases, together with the token embeddings, and zeroes out the remaining. All matrices preserve the identical proportion of nonzero components.
The sparse mannequin has nonzero weights of roughly 1 in 1000. Moreover, the OpenAI group enforced delicate activation sparsity in order that a few quarter of the node activations protecting residual reads, residual writes, consideration channels, and MLP neurons are non-zero.
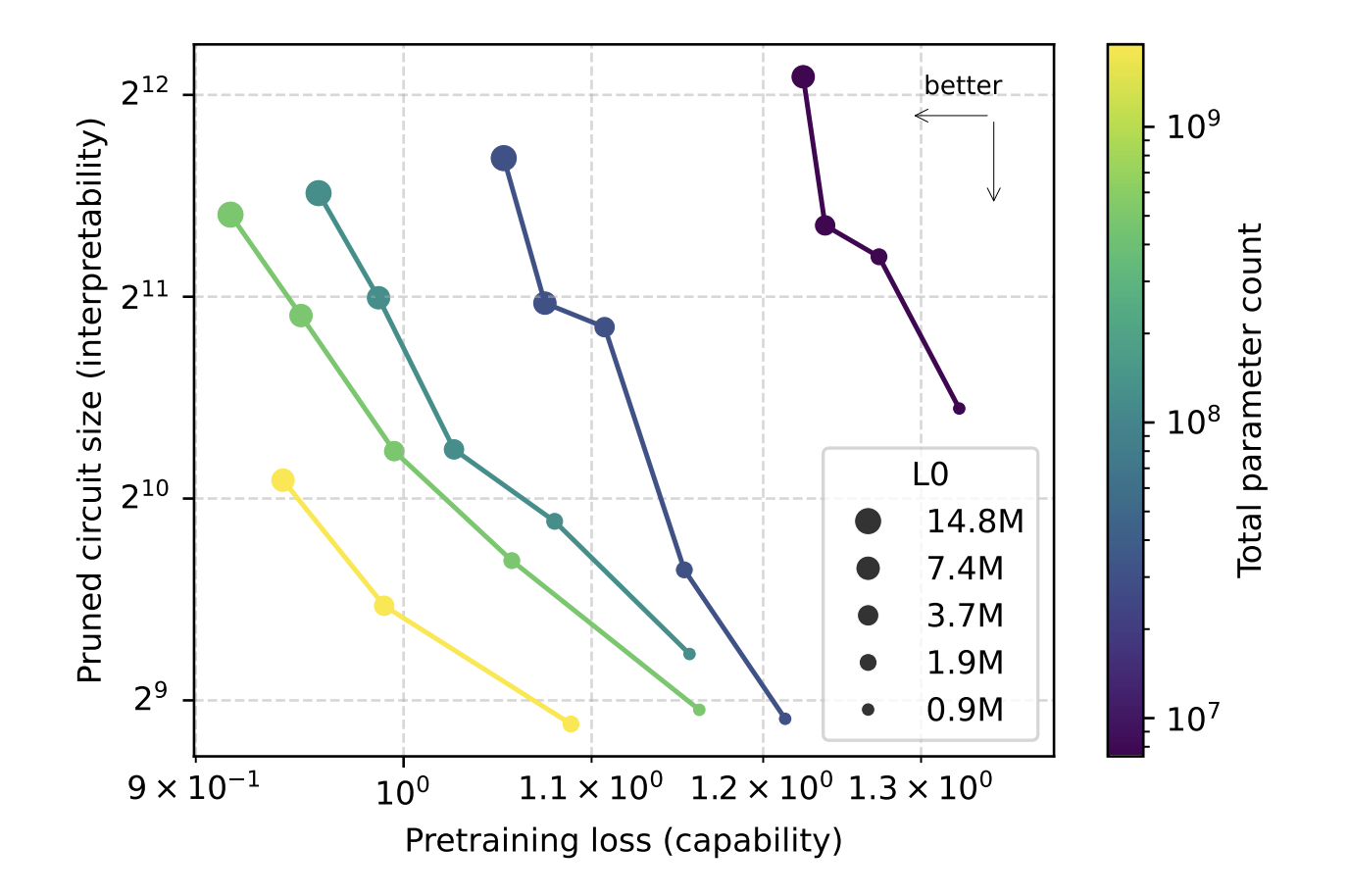
Sparsity is annealed throughout coaching. The mannequin begins with a excessive density after which the allowed non-zero price range regularly strikes in the direction of the goal worth. This design permits the analysis group to scale the width whereas retaining the variety of nonzero parameters mounted and research the tradeoffs between sparsity and energy interpretability as mannequin dimension modifications. The researchers confirmed that for a given pre-training loss, the circuits recovered from the sparse mannequin have been about 16 occasions smaller than the circuits recovered from the dense mannequin.
So what’s a sparse circuit?
The central focus of this analysis work is sparse circuits. The researchers outline nodes at a really wonderful granularity, with every node being a single neuron, an consideration channel, a residual learn channel, or a residual write channel. An edge is a single nonzero entry within the weight matrix that connects two nodes. Circuit dimension is measured by the geometric imply variety of edges between duties.
To discover the mannequin, the analysis group constructed 20 easy Python Subsequent Token binary duties. Every activity forces the mannequin to decide on between two completions that differ by one token. Examples embrace:
single_double_quote, predicts whether or not a string needs to be closed with a single or double quote. Parenthesized rely, determines between ]and ]]based mostly on the depth of checklist nesting. set_or_string, tracks whether or not a variable was initialized as a set or a string.
Prune the mannequin for every activity to seek out the smallest circuit that achieves the goal lack of 0.15 for that activity distribution. Pruning is carried out on the node degree. The eliminated node has its imply worth eliminated and its activation is mounted on the imply worth of the pre-training distribution. The node-wise realized binary masks is optimized utilizing straight-through model surrogates, so the target is a trade-off between activity loss and circuit dimension.
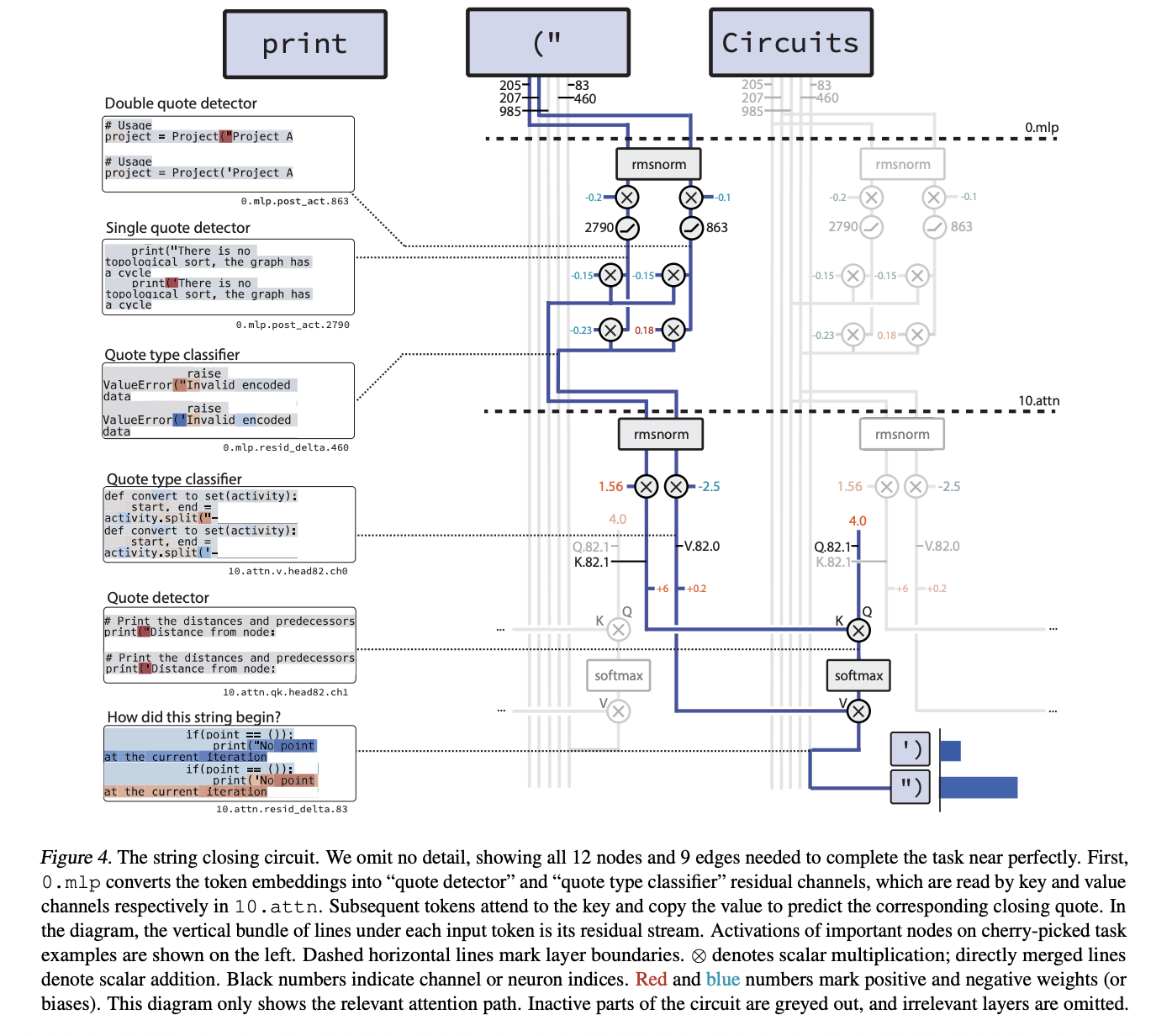
Circuit instance, closing citation bracket and counting bracket
Essentially the most compact instance is the single_double_quote circuit. Right here, the mannequin must specify the opening quote and output the proper closing quote kind. The pruned circuit has 12 nodes and 9 edges.
The mechanism is 2 levels. In layer 0.mlp, two neurons specialise in:
A quotation detection neuron that’s energetic on each ” and ‘” and a quotation kind classifier neuron that’s constructive on ” and unfavorable on ‘
The eye head after layer 10.attn makes use of the quotation detector channel as the important thing and the quotation kind classifier channel as the worth. As a result of the final token incorporates a relentless constructive question, the eye output copies the proper quote kind to the final place and the mannequin closes the string accurately.
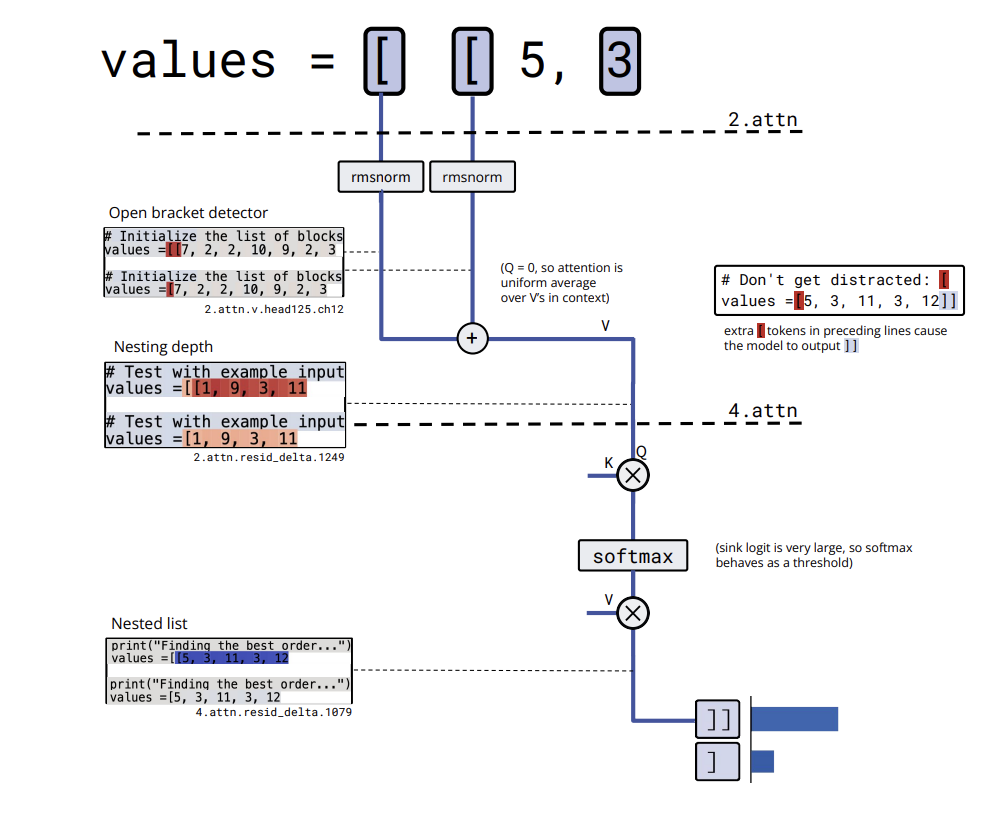
bracket_counting has a barely bigger circuit, however the algorithm is clearer. embedding [ writes into several residual channels that act as bracket detectors. A value channel in a layer 2 attention head averages this detector activation over the context, effectively computing nesting depth and storing it in a residual channel. A later attention head thresholds this depth and activates a nested list close channel only when the list is nested, which leads the model to output ]].
The third circuit (set_or_string_fixedvarname) exhibits how the mannequin tracks the kind of a variable referred to as present. One head copies the present embedding to the set() or “” token. The later head makes use of that embedding as a question and key to repeat again the related data when the mannequin wants to decide on between .add and += .

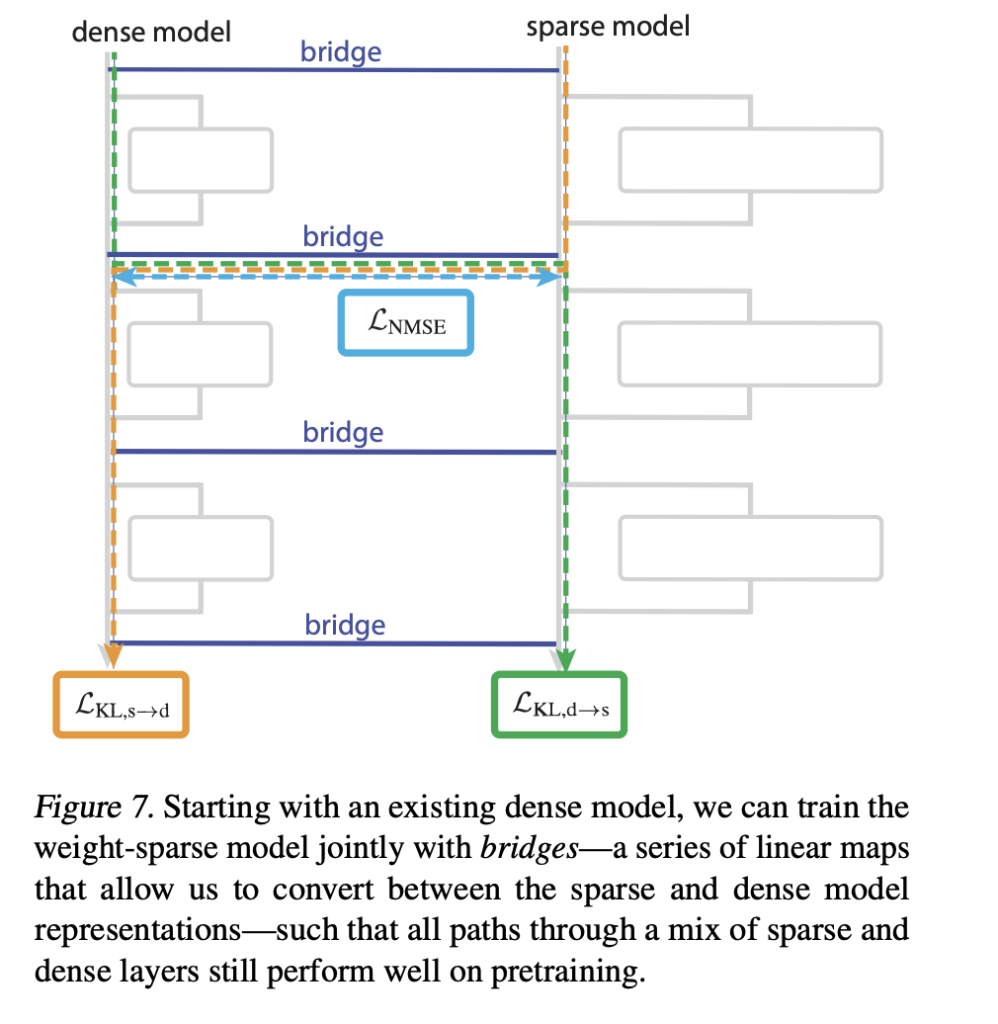
Bridge connecting sparse mannequin to dense mannequin
The analysis group additionally introduces a bridge that connects the sparse mannequin to the already skilled dense mannequin. Every bridge is an encoder-decoder pair that maps dense activations to sparse activations and again once more as soon as per sublayer. The encoder makes use of a linear map with AbsTopK activation, and the decoder is linear.
Coaching provides a loss to encourage a hybrid sparse-dense ahead move to match the unique dense mannequin. This enables the analysis group to perturb interpretable sparse options, such because the quotation kind classifier channel, and map the perturbations to a dense mannequin to alter its conduct in a managed manner.
What precisely has the OpenAI Workforce launched?
The OpenAI group launched the openai/circuit-sparsity mannequin at Hugging Face. It is a 0.4B parameter mannequin tagged with custom_code that corresponds to csp_yolo2 within the analysis paper. This mannequin is used for qualitative outcomes for bracket counts and variable binding. Licensed below Apache 2.0.
Essential factors
Weight sparse coaching as an alternative of post-hoc pruning: Circuit sparse coaching applies excessive weight sparsity throughout optimization to coach a GPT-2 model decoder mannequin. Most weights are zero, so every neuron has just a few connections. Activity-specific small circuits with specific nodes and edges: The analysis group defines circuits on the degree of particular person neurons, consideration channels, and residual channels, and recovers circuits, typically with dozens of nodes and a small variety of edges, for a 20-binary Python next-token activity. Closing quotes and monitoring varieties are totally instantiated circuits. For duties resembling single_double_quote, bracket_counting, and set_or_string_fixedvarname, the researchers used a string closure circuit with 12 nodes and 9 edges to isolate circuits that implement particular algorithms for quote detection, parenthesis depth, and variable kind monitoring. Fashions and instruments on Hugging Face and GitHub: OpenAI has launched the 0.4B parameter openai/circuit-sparsity mannequin on Hugging Face and the entire openai/circuit_sparsity codebase, together with mannequin checkpoints, activity definitions, and circuit visualization UI, on GitHub with Apache 2.0. A bridge mechanism to narrate sparse and dense fashions: This work introduces an encoder-decoder bridge that maps between sparse and dense activations, permitting researchers to switch sparse useful interventions to straightforward dense transformers and research how interpretable circuits relate to actual production-scale fashions.
Verify the load of the paper and mannequin. Be happy to go to our GitHub web page for tutorials, code, and notebooks. Additionally, be at liberty to comply with us on Twitter. Additionally, remember to hitch the 100,000+ ML SubReddit and subscribe to our publication. hold on! Are you on telegram? Now you can additionally take part by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a man-made intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views per thirty days, demonstrating its recognition amongst viewers.



