




Why that is technically essential: Not like earlier “bolstered pretraining” variants that depend on sparse binary correctness alerts or proxy filters, RLP’s dense, validator-free rewards add per-position credit score every time a thought improves a prediction, permitting updates at each token place in a typical web-scale corpus with out exterior validators or curated reply keys.
perceive the outcomes
Qwen3-1.7B-Base: Pre-training with RLP improved the general common for math and science by ~19% in comparison with the bottom mannequin and ~17% in comparison with computational matching steady pre-training (CPT). After the identical post-training (SFT + RLVR) for all variants, the RLP-initialized mannequin maintained a relative benefit of round 7-8% and gained essentially the most on inference-focused benchmarks (AIME25, MMLU-Professional).
Nemotron-Nano-12B v2: Making use of RLP to a 12B hybrid Mamba-Transformer checkpoint elevated the general common from 42.81% to 61.32%, yielding an absolute +23% enchancment in scientific inference (19.8T vs. 20T tokens coaching; RLP (relevant to 250M tokens). This emphasizes knowledge effectivity and architecture-independent habits.
RPT comparability: Beneath matched knowledge and calculations with Omni-MATH model settings, RLP outperformed RPT in math, science, and general common. That is because of the steady info acquisition reward of RLP and the sparse binary sign and entropy filtered tokens of RPT.
Comparability of positioning and post-training RL and knowledge curation
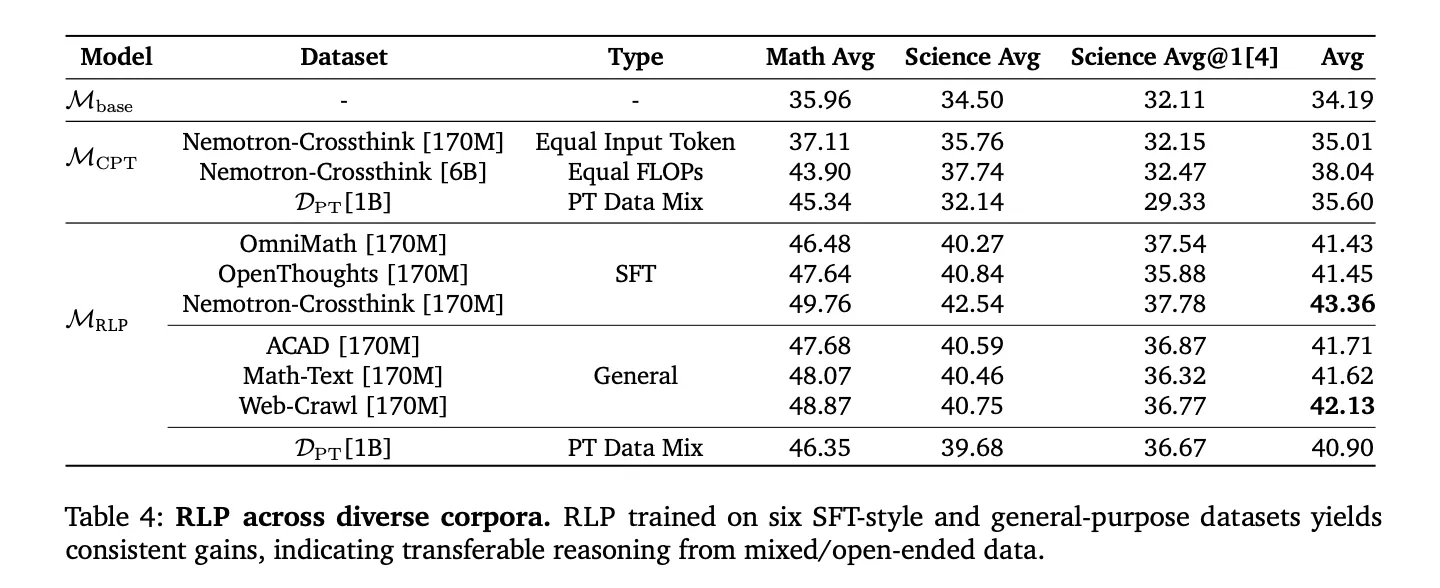
Reinforcement studying pre-training (RLP) is orthogonal to post-training pipelines (SFT, RLVR) and exhibits compound enhancements after customary changes. As a result of rewards are computed from the mannequin’s log proof reasonably than exterior validators, it may be prolonged to domain-independent corpora (internet crawls, educational paperwork, textbooks) and SFT-style inference corpora, avoiding the vulnerabilities of narrowly curated datasets. Within the compute-matched comparability (together with CPT with 35x extra tokens matched to FLOP), RLP nonetheless leads in general common, suggesting that the development comes from the meant design reasonably than the funds.
Essential factors
RLP makes inference a pre-training goal. It samples the thought chain earlier than predicting the subsequent token and rewards info achieve above the no-thinking EMA baseline. Dense per-position alerts with out verifiers: Works on common textual content streams with out exterior graders and permits scalable pre-training updates on each token. Qwen3-1.7B outcomes: +19% vs. base throughout pre-training, +17% vs. compute matched CPT. With an identical SFT+RLVR, RLP maintains as much as 7-8% achieve (most on AIME25, MMLU-Professional). Nemotron-Nano-12B v2: Total common elevated by 42.81% → 61.32% (+18.51 pp, about 35-43% relative) and +23 factors in scientific reasoning attributable to utilizing about 200B fewer NTP tokens. Essential coaching particulars: Replace solely gradients for clipped surrogates and thought tokens with group-relative benefit. Extra rollouts (≈16) and longer pondering intervals (≈2048) would assist. There isn’t any profit to token-level KL anchoring.
conclusion
RLP restructures pre-training to instantly reward “assume earlier than predicting” habits utilizing verifier-free info acquisition alerts, producing sturdy inference positive aspects that persist via the identical SFT+RLVR and scale throughout architectures (Qwen3-1.7B, Nemotron-Nano-12B v2). The aim of this methodology, particularly to distinction CoT conditional chance with a no-sink EMA baseline, integrates cleanly into large-scale pipelines with out handpicked validators, making it a sensible improve to pre-training for the subsequent token reasonably than a post-training add-on.
Try our papers, code, and initiatives pages. Be at liberty to go to our GitHub web page for tutorials, code, and notebooks. Additionally, be happy to comply with us on Twitter. Additionally, remember to hitch the 100,000+ ML SubReddit and subscribe to our e-newsletter. hold on! Are you on telegram? Now you can additionally take part by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a synthetic intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views monthly, demonstrating its recognition amongst viewers.
🙌 Comply with MARKTECHPOST: Add us as your most popular supply on Google.


