



NVIDIA introduced the discharge of Nemotron-Cascade 2, an open weight 30B Combination-of-Specialists (MoE) mannequin with 3B activation parameters. This mannequin focuses on maximizing “intelligence density” and offers superior inference capabilities at a fraction of the parameter scale utilized in frontier fashions. Nemotron-Cascade 2 is the second Open LLM to realize gold medal-level efficiency on the 2025 Worldwide Arithmetic Olympiad (IMO), Worldwide Olympiad in Informatics (IOI), and ICPC World Finals.
Focused efficiency and strategic trade-offs
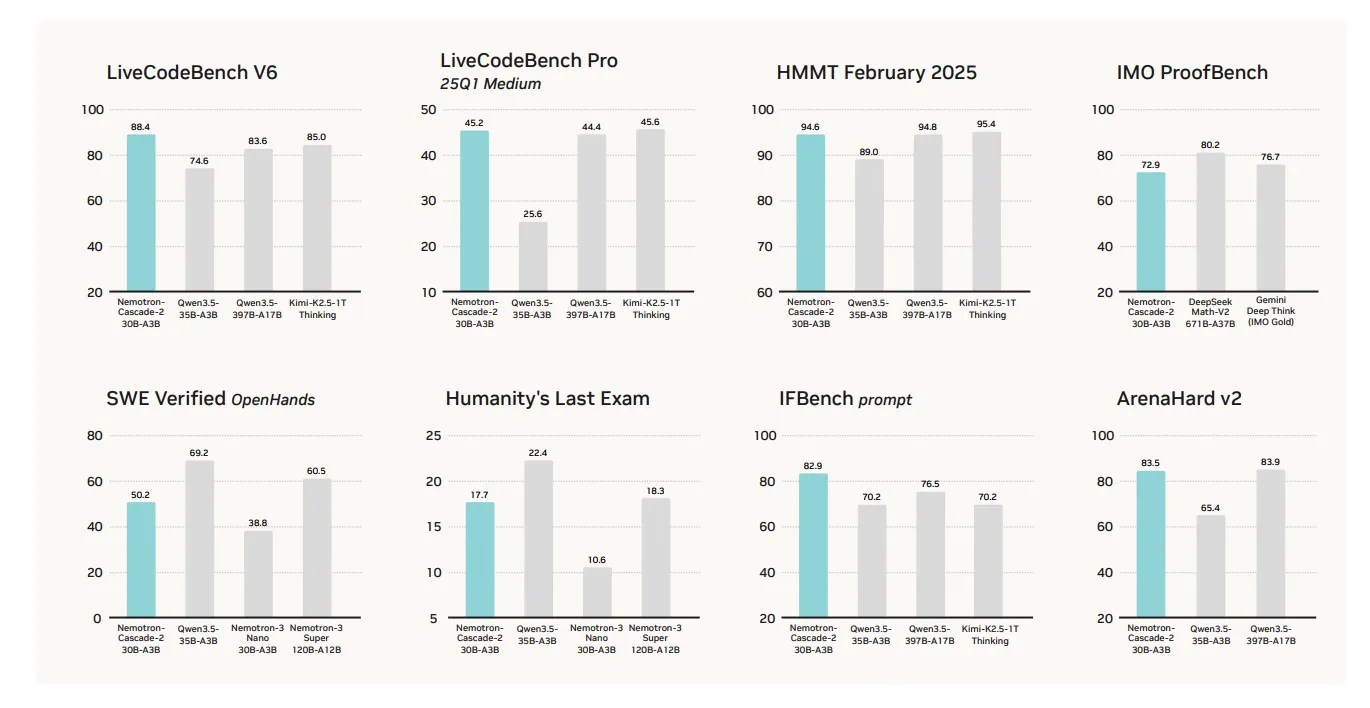
Nemotron-Cascade 2’s predominant worth proposition is specialised efficiency in mathematical reasoning, coding, alignment, and instruction following. Though we obtain state-of-the-art leads to these key inference-intensive areas, we don’t obtain “all-out wins” on each benchmark.
The efficiency of this mannequin is best in a number of goal classes in comparison with the not too long ago launched Qwen3.5-35B-A3B (February 2026) and the bigger Nemotron-3-Tremendous-120B-A12B.
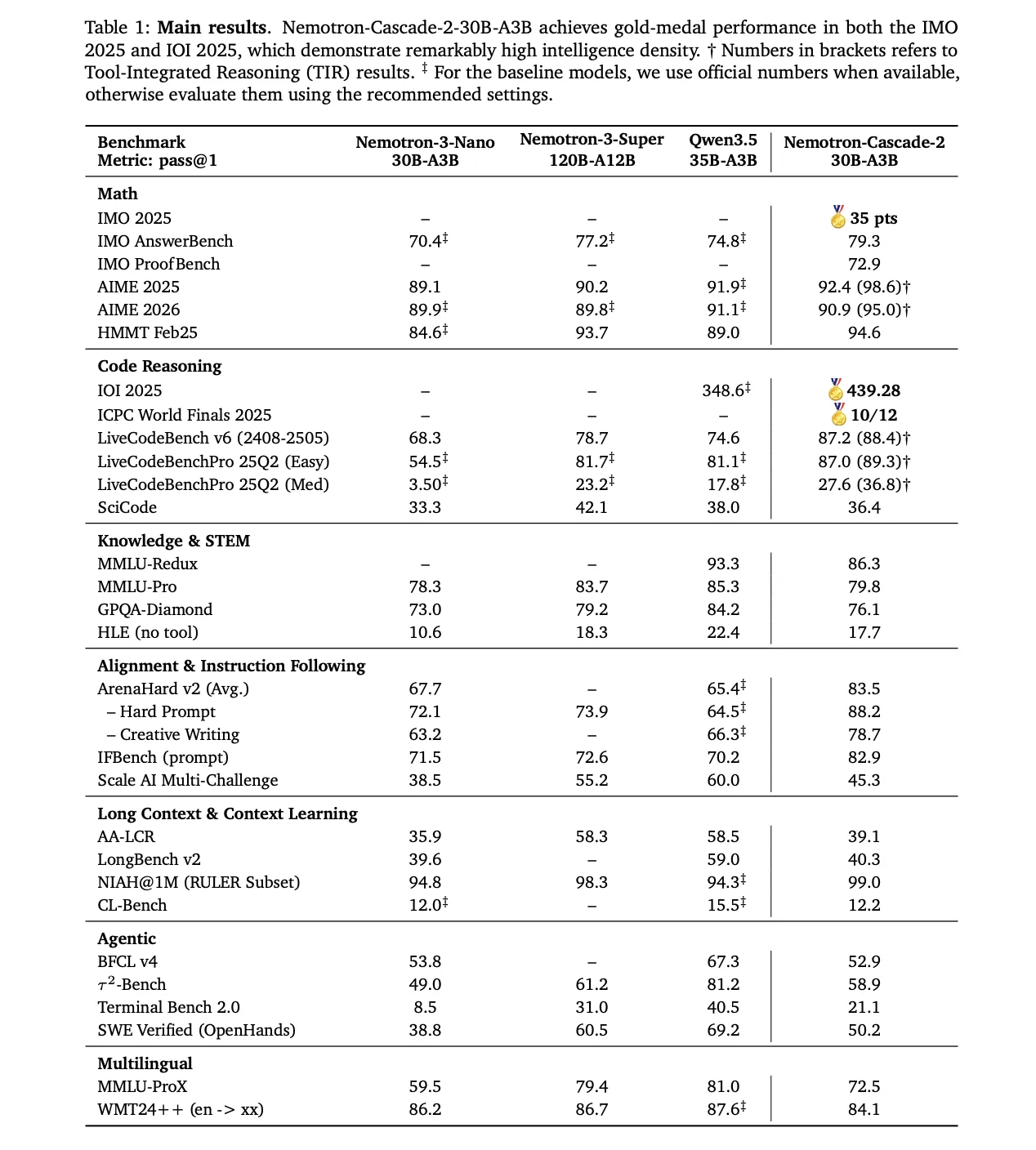
Mathematical Reasoning: Outperforms Qwen3.5-35B-A3B in AIME 2025 (92.4 vs. 91.9) and HMMT Feb25 (94.6 vs. 89.0). Coding: Leads in LiveCodeBench v6 (87.2 vs. 74.6) and IOI 2025 (439.28 vs. 348.6+). Changes and directions beneath: Scores are considerably increased on ArenaHard v2 (83.5 vs. 65.4+) and IFBench (82.9 vs. 70.2).
Technical structure: Cascade RL and Multi-Area On-Coverage Distillation (MOPD)
The mannequin’s inference capabilities come from a post-training pipeline beginning with the Nemotron-3-Nano-30B-A3B-Base mannequin.
1. Supervised Superb-Tuning (SFT)
Throughout SFT, the NVIDIA analysis group utilized a meticulously curated dataset through which samples had been packed into sequences of as much as 256,000 tokens. The dataset included:
1.9 million Python inference traces and 1.3 million Python instrument name samples for aggressive coding. 816K samples for mathematical pure language proofs. Specialised Software program Engineering (SWE) mix consisting of 125K agent samples and 389K agentless samples.
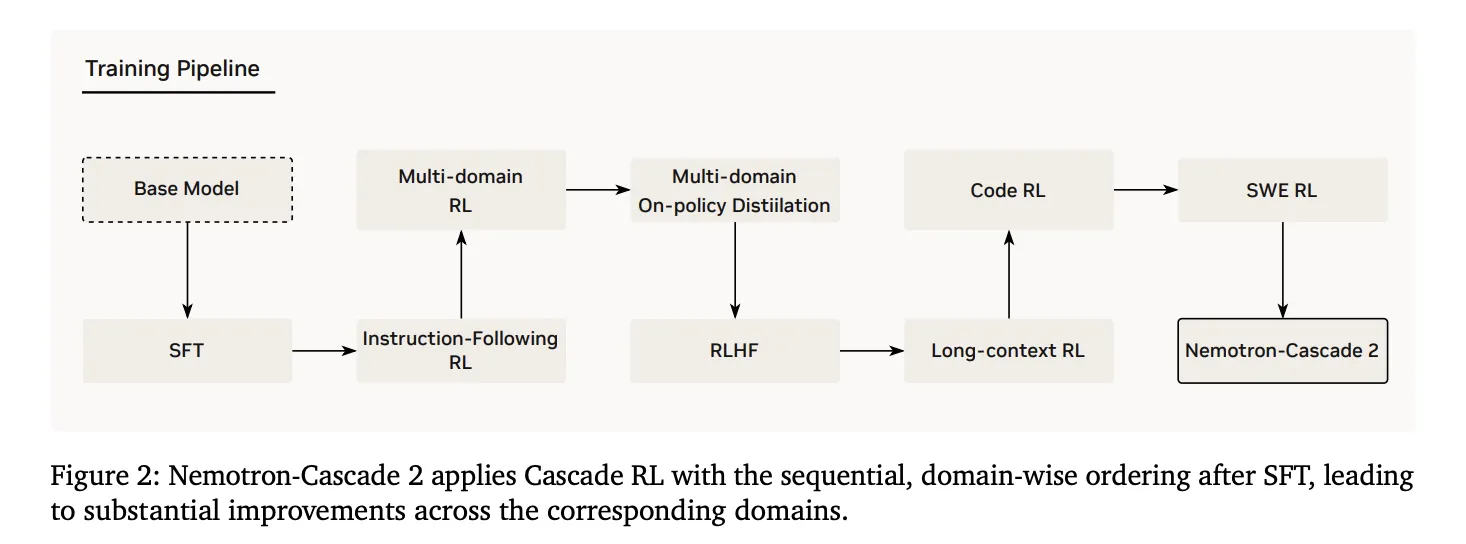
2. Cascade reinforcement studying
Following SFT, the mannequin underwent Cascade RL to use sequential domain-wise coaching. This enables hyperparameters to be tuned to a particular area with out destabilizing different parameters, thus stopping catastrophic forgetting. The pipeline contains phases for instruction following (IF-RL), multidomain RL, RLHF, lengthy context RL, particular code, and SWE RL.
3. Multi-domain on-policy distillation (MOPD)
A key innovation of Nemotron-Cascade 2 is the mixing of MOPD through the Cascade RL course of. MOPD meeting offers the advantages of dense token-level distillation utilizing the best-performing intermediate “supervised” mannequin already derived from the identical SFT initialization. This benefit is mathematically outlined as:
$$a_{t}^{MOPD}=log~pi^{domain_{t}}(y_{t}|s_{t})-log~pi^{prepare}(y_{t}|s_{t})$$
The analysis group discovered that MOPD is considerably extra pattern environment friendly than sequence-level reward algorithms like group relative coverage optimization (GRPO). For instance, in AIME25, MOPD reached teacher-level efficiency (92.0) inside 30 steps, whereas GRPO might solely obtain 91.0 even by matching these steps.
Interplay between the inference perform and the agent
Nemotron-Cascade 2 helps two predominant modes of operation by chat templates.
Considering mode: Began by a single token adopted by a newline. This allows deep reasoning for complicated math and code duties. Non-thinking mode: activated by prepending an empty block for a extra environment friendly and direct response.
For agent duties, the mannequin makes use of a structured instrument invocation protocol inside system prompts. The accessible instruments are listed throughout the tag, and the mannequin is instructed to carry out the instrument calls wrapped within the tag to make sure verifiable execution suggestions.
By specializing in “intelligence density,” Nemotron-Cascade 2 demonstrated that specialised inference skills, beforehand regarded as the unique area of frontier-scale fashions, are achievable at 30B scale by domain-specific reinforcement studying.
Take a look at the HF paper and mannequin. Additionally, be happy to observe us on Twitter. Additionally, remember to affix the 120,000+ ML SubReddit and subscribe to our publication. hold on! Are you on telegram? Now you can additionally take part by telegram.


