



Giant-scale Language Fashions (LLMS) stand on the coronary heart of numerous AI breakthroughs, together with chatbots, coding assistants, query solutions, and artistic writing. Nonetheless, regardless of their prowess, they continue to be stateless. Every question arrives with out remembering what has come earlier than. Their mounted context home windows are unable to build up persistent information throughout lengthy conversations and multi-session duties, struggling to deduce complicated histories. Latest options like Searched Technology (RAG) add previous data to the immediate, which regularly results in a loud, unfiltered context.
A staff of researchers from the College of Munich, the Institute of Know-how in Munich, the College of Cambridge and the College of Hong Kong launched the Reminiscence-R1. This can be a framework that teaches LLM brokers to resolve what to recollect and the best way to use them. Its LLM brokers study to actively handle and make the most of exterior reminiscence. Decide what so as to add, replace, take away, or ignore noise when answering a query. Breakthrough? These behaviors are educated in reinforcement studying (RL) utilizing solely results-based rewards, which requires minimal supervision and robustly generalize throughout fashions and duties.
However why does LLMS have a tough time remembering?
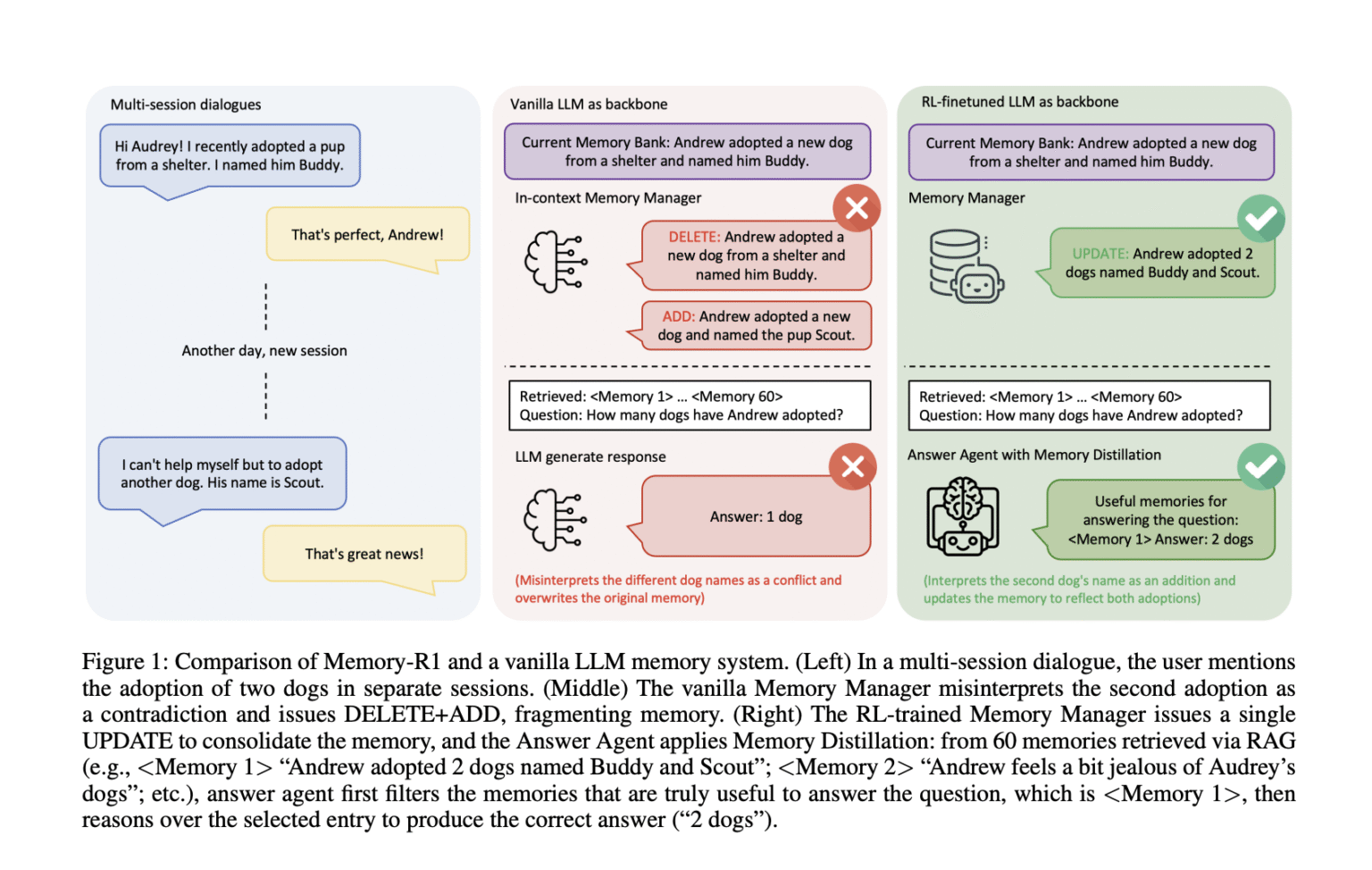
Think about a multi-session dialog. Within the first session, the consumer says, “We adopted a canine named Buddy.” They then added, “we adopted one other canine referred to as Scout.” Ought to the system change the primary assertion with the second assertion, merge them, or ignore the replace? Vanilla reminiscence pipelines typically fail. You can erase “buddies” and add “scouts” to misread new data as inconsistencies moderately than integration. Over time, such methods turn into inconsistent and fragment moderately than evolve the consumer’s information.
The RAG system will get data, however do not filter it: irrelevant entries contaminate inference and the mannequin is distracted by noise. In distinction, people get broadly, however selectively filter what’s vital. Most AI reminiscence methods are static and depend on hand-crafted heuristics to recollect moderately than studying from suggestions.
Reminiscence-R1 Framework
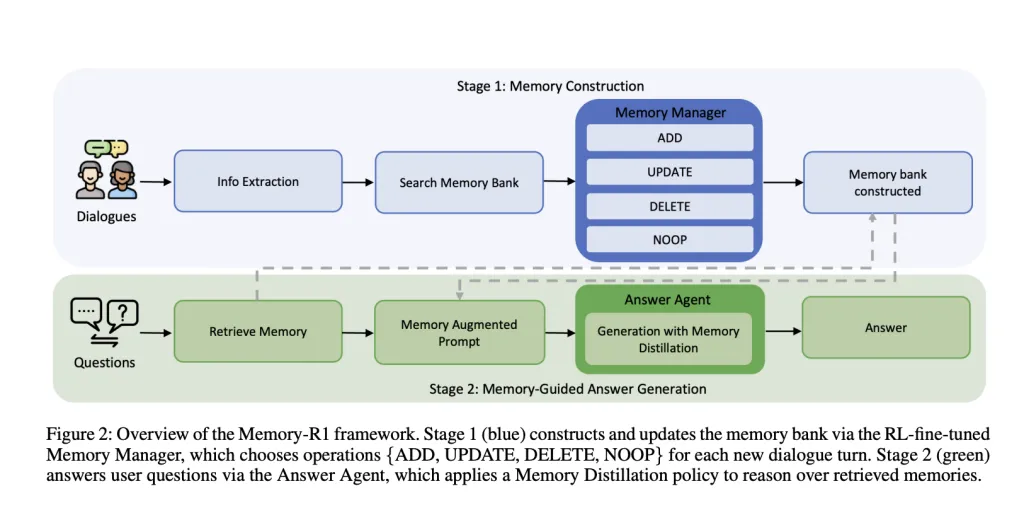
Reminiscence-R1 is constructed round two specialised RL-Effective-Tuned brokers.
Reminiscence Supervisor: Determines the reminiscence operations (add, replace, delete, noop) to carry out after every dialog has rotated, and dynamically updates exterior reminiscence banks. Reply Agent: For every consumer query, retrieves recollections of as much as 60 candidates, distills them into essentially the most related subset, and generates solutions via this filtered context.
Each parts are educated with a reinforcement studying RL. This solutions the query as a reward sign utilizing both proximal coverage optimization (PPO) or group relative coverage optimization (GRPO). Which means as a substitute of requiring handbook labeled reminiscence operations, brokers study by trial and error to optimize last activity efficiency.
Reminiscence Supervisor: Be taught to edit information
After every dialog is rotated, LLM extracts vital details. The reminiscence supervisor retrieves the associated entries from the reminiscence financial institution and selects the operation.
Add: Inserts new data that doesn’t exist already. Replace: When detailing or bettering earlier details, we fuse new particulars into current recollections. Delete: Delete outdated or inconsistent data. NOOP: If no associated gadgets have been added, depart reminiscence unchanged.
Coaching: Reminiscence Supervisor is up to date primarily based on the standard of the solutions generated from the newly edited reminiscence financial institution by the Response Agent. Reminiscence operations enable the answering agent to reply precisely, the reminiscence supervisor receives a optimistic reward. This result-driven reward eliminates the necessity for costly handbook annotations for reminiscence operations.
Instance: When a consumer first mentions adopting a canine referred to as Buddy, they add that they then adopted one other canine referred to as Scout. The vanilla system could take away “buddies” and add “scouts” and deal with them as inconsistencies. Nonetheless, RL-trained reminiscence managers have up to date their reminiscence saying “Andrew adopted two canines, Buddy and Scout,” sustaining a constant, evolving information base.
Ablation: RL fine-tuning considerably improves reminiscence administration. PPOs and GRPOs are higher than heuristic-based managers throughout the context. The system learns to combine information moderately than fragments.
Reply Agent: Selective reasoning
For every query, the system will retrieve recollections of as much as 60 candidates in RAG. However as a substitute of feeding all of this to LLM, the reply agent will first distill the set. Solely keep essentially the most related entries. Solely then will it generate a solution.
Coaching: Reply brokers are additionally educated in RL and use the precise match between their reply and the gold reply as reward. This encourages specializing in noise and inference exclusion in prime quality contexts.
Instance: I used to be requested, “Does John reside close to the seaside or the mountains?” Vanilla LLM could output “mountains” influenced by unrelated recollections. Nonetheless, Reminiscence-R1 answering brokers solely floor beach-related entries earlier than answering, resulting in right “seaside” responses.
Ablation: RL fine-tuning improves reply high quality over static search. Distillation of reminiscence (elimination of unrelated recollections) additional enhances efficiency. A stronger reminiscence supervisor means even higher earnings and reveals improved compound curiosity.
Coaching Information Effectivity
Reminiscence-R1 is extremely knowledge environment friendly. Solely 152 query reply pairs for coaching present sturdy outcomes. That is doable as a result of brokers study from the outcomes, not from 1000’s of hand-signed reminiscence operations. Supervision is stored to a minimal, and the system expands to a big, real-world dialogue historical past.
The locomo benchmark used for analysis consists of a multi-turn dialog (roughly 600 revolutions per dialog, averaged 26,000 tokens) and related QA pairs spanning single hops, multi-hops, open domains, and temporal inference.
Experimental outcomes
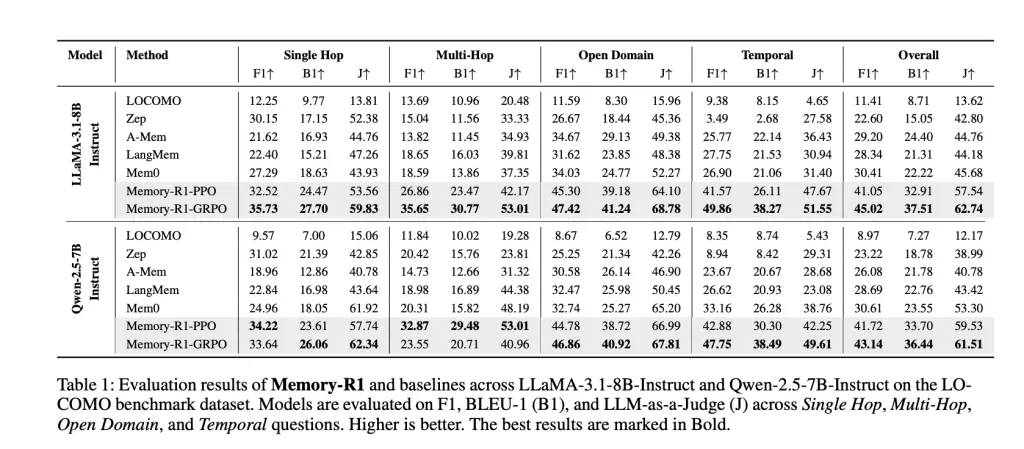
Reminiscence-R1 was examined with the llama-3.1-8b-instruct and qwen-2.5-7b-instruct spine towards aggressive baselines (Mocomo, Zep, A-Mem, Langmem, MEM0). The important thing metrics are:
F1: Measures overlap between predicted solutions and proper solutions. BLEU-1: Seize vocabulary similarity on the unigram degree. LLM-as-a-judge: Makes use of particular person LLMs to evaluate de facto accuracy, relevance, and completeness. This can be a proxy for human judgment.
Outcomes: Reminiscence-R1-Grpo achieves the perfect total efficiency, bettering MEM0 (beforehand the perfect baseline) by 48% for F1, 69% for BLEU-1, and 37% for LLM-AS-A-Decide with LLAMA-3.1-8B. Comparable advantages might be seen with Qwen-2.5-7b. The enhancements are broad, spanning all query sorts and generalised throughout mannequin architectures.
Why is that this vital?
Reminiscence-R1 reveals you possibly can study reminiscence administration and utilization. LLM brokers don’t must depend on weak heuristics. By figuring out the result-driven RL, the system: system:
As conversations evolve, they routinely combine information moderately than fragment or overwrite it. Removes noise when answering, bettering the efficient accuracy and high quality of reasoning. Be taught effectively by increasing into real-world elder duties with little oversight. It has turn into a promising basis for memory-recognized AI methods, generalising your entire mannequin, and next-generation brokers.
Conclusion
Reminiscence R1 UNSHACKLES LLM brokers are brokers from stateless constraints, giving them the flexibility to discover ways to successfully handle and use long-term reminiscence. By framing reminiscence operations and filtering them as RL points, we obtain cutting-edge efficiency with minimal oversight and powerful generalization. This can be a main step in direction of AI methods that not solely converse fluently, but additionally promote richer, extra lasting, extra helpful experiences which might be human-like and extra helpful to customers.
FAQ
FAQ 1: Why is Reminiscence-R1 higher than a typical LLM reminiscence system?
Reminiscence-R1 is the usage of reinforcement studying to actively management reminiscence. This determines which data so as to add, replace, delete, or keep.
FAQ 2: How does Reminiscence-R1 enhance the standard of solutions from lengthy dialog historical past?
Reply Agent applies the “Reminiscence Distillation” coverage. To floor solely essentially the most related to every query, we filter as much as 60 recovered recollections, and scale back noise and enhance de facto accuracy in comparison with merely passing all of the context to the mannequin.
FAQ 3: Is Reminiscence R1 environment friendly for coaching?
Sure, Reminiscence-R1 achieves cutting-edge advantages utilizing solely 152 QA coaching pairs, as results-based RL rewards get rid of the necessity for expensive handbook annotations for every reminiscence operation.
Please see this paper. For tutorials, code and notebooks, please go to our GitHub web page. Additionally, be at liberty to comply with us on Twitter. Remember to hitch 100K+ ML SubredDit and subscribe to our publication.
Asif Razzaq is CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, ASIF is dedicated to leveraging the probabilities of synthetic intelligence for social advantages. His newest efforts are the launch of MarkTechPost, a man-made intelligence media platform. That is distinguished by its detailed protection of machine studying and deep studying information, and is simple to grasp by a technically sound and huge viewers. The platform has over 2 million views every month, indicating its reputation amongst viewers.


