




A set of recent open supply fashions GahahgIe Gemma 4 The household has arrived. Open supply fashions have grow to be highly regarded as of late resulting from privateness considerations and the pliability to simply tweak them. There are at the moment 4 versatile open supply fashions within the Gemma 4 household, which on paper look very promising. So, with out additional ado, let’s decipher and see what the hype is all about.
gemma household
Gemma is a household of light-weight, open-weight, large-scale language fashions developed by Google. It is constructed utilizing the identical analysis and expertise that powers Google’s Gemini mannequin, however designed to be extra accessible and environment friendly.
What this implies in apply is that the Gemma mannequin is meant to run in additional sensible environments resembling laptops, shopper GPUs, and even cellular units.
There are each varieties:
Primary model (for fine-tuning and customization) Instruction Adjustment (IT) model (for chat and basic use)
The fashions that fall below the Gemma 4 household are:
Gemma 4 E2B: A multimodal mannequin with roughly 2B efficient parameters and optimized for edge units resembling smartphones. Gemma 4 E4B: Just like the E2B mannequin, however this comes with as much as 4B lively parameters. Gemma 4 26B A4B: This can be a combination of 26B parameters within the professional mannequin and solely prompts 3.8B parameters (~4B lively parameters) throughout inference. A quantized model of this mannequin may be run on shopper GPUs. Gemma 4 31B: A dense mannequin with 31B parameters, it’s the strongest mannequin on this lineup and may be very appropriate for fine-tuning functions.
The E2B and E4B fashions have a 128K context window, and the bigger 26B and 31B have a 256K context window.
Observe: All fashions can be found as each base fashions and “IT” (Instruction Tailor-made) fashions.
Beneath are the benchmark scores for the Gemma 4 mannequin.
Foremost options of Gemma 4
Code technology: Gemma 4 fashions can be utilized for code technology and have good LiveCodeBench benchmark scores. Agent methods: Gemma 4 fashions can be utilized regionally inside agent workflows or built-in into self-hosted, production-grade methods. Multilingual methods: These fashions are skilled in over 140 languages and can be utilized to help a wide range of languages and translation functions. Superior brokers: These fashions have vital enhancements in arithmetic and reasoning in comparison with earlier fashions. These can be utilized by brokers that require multi-step planning and pondering. Multimodality: These fashions can inherently course of photographs, video, and audio. It may be used for duties resembling OCR and speech recognition.
How do I entry Gemma 4 through Hugface?
Gemma 4 is launched below the Apache 2.0 license, supplying you with the liberty to construct along with your fashions and deploy them in any setting. These fashions may be accessed utilizing Hugging Face, Ollama, and Kaggle. Let’s take a look at “Gemma 4 26B A4B IT” by means of Hugging Face’s inference supplier. This may help you higher perceive the performance of your mannequin.
Stipulations
Hug face token:
Go to https://huggingface.co/settings/tokens. Create a brand new token, set a reputation, and verify the field under earlier than creating the token.
Hold your hug face tokens useful.
Python code
We are going to use Google Colab for the demo. Be happy to make use of no matter you want.
from getpass import getpass hf_key = getpass(“Please enter your hug face token: “)
Paste the Hugging Face token when prompted.

Let’s create a entrance finish for an e-commerce web site to see how the mannequin works.
Immediate=””” Generate a contemporary, visually interesting entrance finish in your e-commerce web site utilizing solely HTML and inline CSS (no exterior CSS or JavaScript). Pages embody responsive layouts, navigation bars, hero banners, product grids, classes It ought to embody sections, product playing cards with photographs/costs/buttons, and a footer. Use a clear, fashionable design, good spacing, and a laptop-friendly format.
Ship a request to the inference supplier.
Import OS from Hugging Face Hub Import InferenceClient consumer = InferenceClient( api_key=hf_key, ) accomplished = consumer.chat.completions.create(mannequin=”google/gemma-4-26B-A4B-it:novita”,messages=)[
{
“role”: “user”,
“content”: [
{
“type”: “text”,
“text”: prompt,
},
]} ], ) print(completion.selections[0]. message)
Copy the code and create the HTML and you’re going to get the next consequence:
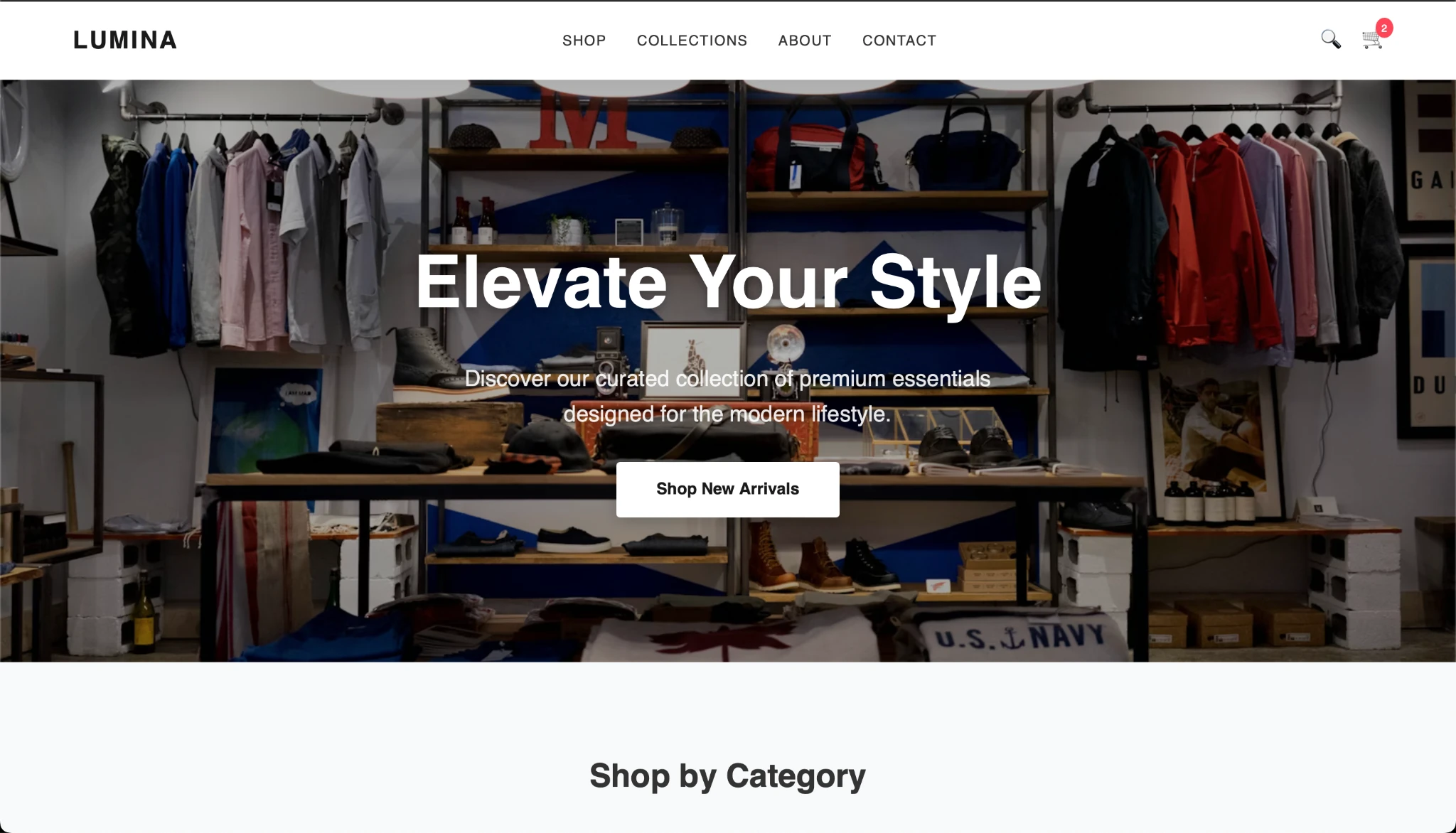
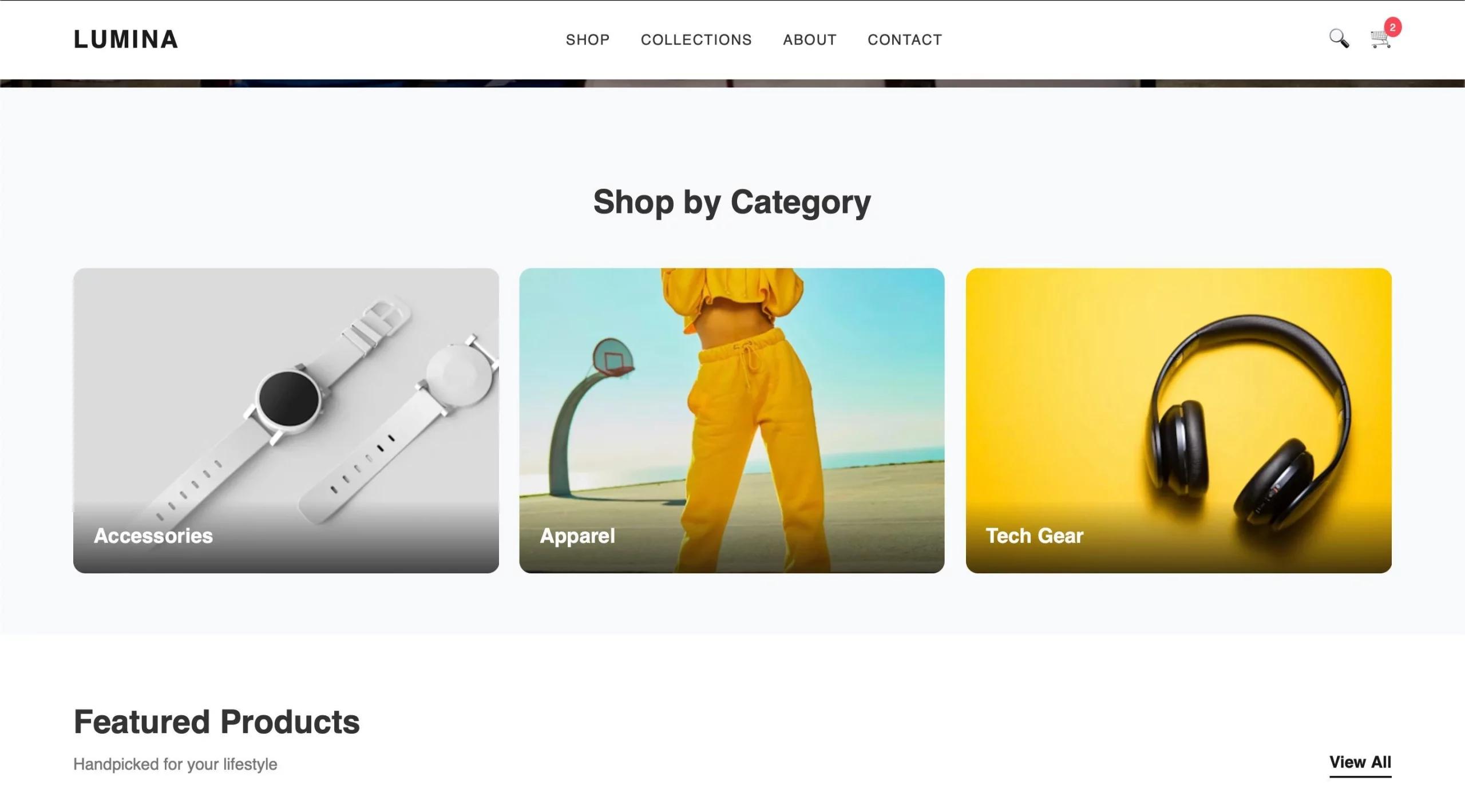
The output is sweet and the Gemma mannequin appears to carry out properly. What do you suppose?
conclusion
The Gemma 4 household seems promising on paper and in outcomes. With versatile options and a wide range of fashions constructed to swimsuit totally different wants, the Gemma 4 mannequin will get a whole lot of issues proper. And with the rising recognition of open supply AI, you want choices to attempt, take a look at, and discover fashions that higher fit your wants. It would even be fascinating to see how cellular, Raspberry Pi and different units profit from evolving memory-efficient fashions sooner or later.
FAQ
A. E2B means 2.3B efficient parameters. In the meantime, the entire parameters together with embedding attain about 5.1B.
A. Massive embedded tables are primarily used for lookup operations, in order that they enhance the entire parameters however don’t enhance the efficient computational measurement of the mannequin.
A. Professional mixing prompts solely a small subset of the specialised professional community for every token, growing effectivity whereas sustaining excessive mannequin capability. Gemma 4 26B is a MoE mannequin.
![]()
Enthusiastic about expertise and innovation, I graduated from Vellore Institute of Know-how. At present, I’m working primarily on knowledge science as a knowledge science trainee. He has a deep curiosity in deep studying and generative AI and is keen about exploring cutting-edge strategies to resolve complicated issues and create impactful options.
Log in to proceed studying and luxuriate in content material hand-picked by our consultants.
Proceed studying at no cost


