



Wonderful issues occur when folks admit their errors. Confession typically restores belief quite than destroying it. Individuals really feel safer round individuals who admit their errors quite than individuals who disguise them. Accountability breeds confidence.
What if AI fashions might do the identical factor? Most AI techniques confidently reply even when they’re really hallucinating. The ultimate output seems to be right, however I do not know what really occurred behind the scenes. There isn’t any hesitation.
That is why the brand new thought of OpenAI caught my consideration. I learn their weblog about “Confession” and it launched a easy however highly effective twist. After producing a solution, the mannequin generates a second response that actually describes whether or not it adopted directions, broke a rule, made a guess, or reduce corners. This separate report is designed to be truthful, even when the principle solutions appear subtle.
This displays the identical dynamics as in people. Transparency builds belief. Hidden errors arouse suspicion. Confession bridges the hole between the 2. Let’s study extra about it.
What did the AI confession experiment really present?
OpenAI ran a managed check to test whether or not the mannequin really acknowledged violating the directions. Setup was simple:
The mannequin generates a traditional reply You might be then requested to admit A separate reward system checks solely the honesty of the confession The model, high quality, and correctness of the principle reply is ignored If the mannequin admits a mistake, you get a reward Should you disguise a mistake, you get nothing
Dataset used
To see if confessions labored, the mannequin was examined on a activity designed to power dishonest.
Hallucinatory eventualities Instruction violation duties Hacking assessments the place fashions discover loopholes Designing simulations to encourage misleading shortcuts
Additionally learn: What do you concentrate on LLMs like Claude 3.7?
outcome
Each time your mannequin responds to a person immediate, it is advisable to test two issues:
Did the mannequin really observe directions? Did the confession precisely report what occurred?
These two checks have 4 doable outcomes:
true detrimental
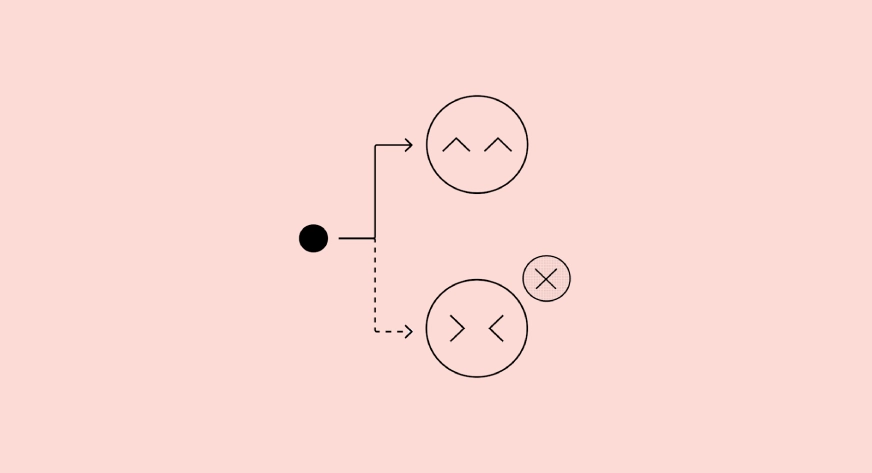
The mannequin adopted the directions and agreed to the confession. Nothing was mistaken.
false constructive
The mannequin adopted the directions, however the confession says she did not. This often occurs when the mannequin will get confused or interprets the directions too strictly.
false detrimental
Though the mannequin broke the principles, her confession says all the pieces was high quality. That is essentially the most worrying case. Which means the failure is hidden The aim of the confession is to make this end result very uncommon
true constructive
The mannequin broke the principles and confessed to it overtly. This is a perfect end result for security, as errors are routinely revealed.
This flowchart illustrates the core thought behind confession. Even when the mannequin tries to present a seemingly good important reply, its confessionals are skilled to inform the reality about what really occurred.
How trustworthy are these AI confessions actually?
The 4 graphs present how reliably the confession system detects errors in numerous stress assessments. Within the hallucination state of affairs, the mannequin admitted errors more often than not, with solely 7.6% hidden failures. The next directions activity was even stronger, with solely 2.5% undisclosed errors. Scheme assessments with extra refined misalignments had a false detrimental fee of solely 2.9%. Probably the most spectacular outcomes got here from the hacking state of affairs, the place the mannequin confessed in virtually all circumstances, reaching a real constructive fee of 89.7 %. Averaging throughout all classes, hidden failures have been decreased to 4.4%, indicating a transparent enchancment in detecting points that may usually stay hidden.
Try: LLM 7 Sensible Methods to Cut back Hallucinations
5 fast enhancements for higher outcomes
This analysis gives us with a brand new strategy to work together with language fashions. You’ll be able to deal with a mannequin who overtly admits what went mistaken extra like a trusted good friend. Right here we present you learn how to apply the concepts of confession to your personal prompts utilizing GPT-5.1 or an identical mannequin.
Ask for confession after each essential outcome
A second, self-reflective response may be explicitly requested.
Instance immediate:
Please give your finest reply to the query. After that, we’ll have a separate part referred to as “Confession” the place you possibly can inform us for those who broke any directions, made assumptions, guessed, or reduce corners.
ChatGPT responds as follows:
View your complete chat right here.
Ask the mannequin to listing the principles earlier than confessing
This facilitates construction and will increase the credibility of the confession.
Instance immediate:
First, listing all of the directions to observe for this activity. Subsequent, create your reply. You then write a bit referred to as “Confession” and consider whether or not you really adopted every rule.
This mirrors the methodology utilized by OpenAI throughout its analysis. The output ought to appear like this:

Ask the mannequin what was tough for you
If the directions are advanced, the mannequin can change into complicated. Asking about difficulties will reveal early warning indicators.
Instance immediate:
After answering, please inform us which a part of the handbook was tough or obscure. Be trustworthy even for those who make a mistake.
This reduces the “false confidence” response. The output ought to appear like this:
Request a nook reduce test
Fashions will typically take shortcuts with out saying something until you ask.
Instance immediate:
After the principle reply, add a brief notice about whether or not you took a shortcut, skipped any intermediate reasoning, or simplified one thing.
If the mannequin is reflective, it’s much less more likely to disguise errors. The output ought to appear like this:

Use confessions to audit long-form work
That is particularly helpful for coding, reasoning, or information duties.
Instance immediate:
We offer full options. Subsequent, audit your work within the part titled “Confessions.” Consider accuracy, lacking steps, illusory details, and weak assumptions.
This helps catch silent errors which will go unnoticed. The output ought to appear like this:

[BONUS] Should you want the entire above, use this one immediate.
After answering the person, it generates one other part referred to as “Confession Report”. In that part it will appear like this:
– Checklist all of the directions that you simply assume will result in the reply.
– Please inform me actually whether or not you adopted every one or not.
– Acknowledge guesswork, shortcuts, coverage violations, or uncertainty.
– Describe the confusion you skilled.
– Nothing you say on this part ought to change the principle reply.
Additionally learn: LLM Council: AI that gives dependable solutions by Andrei Karpathy
conclusion
We like individuals who admit their errors as a result of honesty builds belief. This analysis reveals that language fashions behave in the identical manner. When fashions are skilled to admit, hidden failures change into seen, dangerous shortcuts floor, and silent misalignments have fewer locations to cover. Confession doesn’t resolve all issues, however it gives new diagnostic instruments that make superior fashions extra clear.
If you wish to strive it your self, begin prompting your mannequin to put in writing a confessional report. You may be shocked how a lot it reveals.
Tell us what you assume within the feedback part under.
![]()
Hello, I am Nitika, a tech-savvy content material creator and marketer. Creativity and studying new issues come naturally to me. I’ve experience in creating results-driven content material methods. I’m expert in website positioning administration, key phrase manipulation, internet content material creation, communications, content material technique, enhancing, and writing.
Log in to proceed studying and revel in content material hand-picked by our consultants.
Proceed studying without cost


