




Writing a analysis paper is hard. Even after the experiment is over, researchers face weeks of translating messy analysis notes, scattered consequence sheets, and half-formed concepts into polished, logically coherent manuscripts that adhere exactly to convention specs. For a lot of new researchers, the interpretation course of is the place the paper dies.
A crew at Google Cloud AI Analysis proposes a multi-agent system that autonomously transforms unstructured pre-written supplies (tough thought summaries and uncooked experiment logs) into submittable LaTeX manuscripts, full with literature critiques, generated figures, and API-verified citations.
core downside to resolve
Earlier automated writing methods like PaperRobot had been in a position to generate incremental textual content sequences, however had been unable to deal with the complete complexity of data-driven scientific narratives. Latest end-to-end autonomous analysis frameworks, corresponding to AI Scientist-v1 (which introduces automated experimentation and drafting by means of code templates) and its successor AI Scientist-v2 (which makes use of agent tree search to reinforce autonomy), automate all the analysis loop, however their authoring modules are tightly coupled with their very own inner experimentation pipelines. You may’t simply hand over your knowledge and count on to obtain a paper. They aren’t unbiased writers.
Alternatively, specialised methods for literature critiques, corresponding to AutoSurvey2 and LiRA, generate complete surveys however lack the context consciousness to create focused, related analysis sections that clearly place particular new strategies in opposition to typical methods. CycleResearcher requires an present structured BibTeX bibliography checklist as enter, an artifact that’s not often accessible once you begin writing, and fails fully with unstructured enter.
Consequently, a niche was created. Current instruments can not take unconstrained human-provided materials (the type that actual researchers even have after finishing an experiment) and produce a whole and rigorous manuscript on their very own. PaperOrchestra is purpose-built to fill that hole.
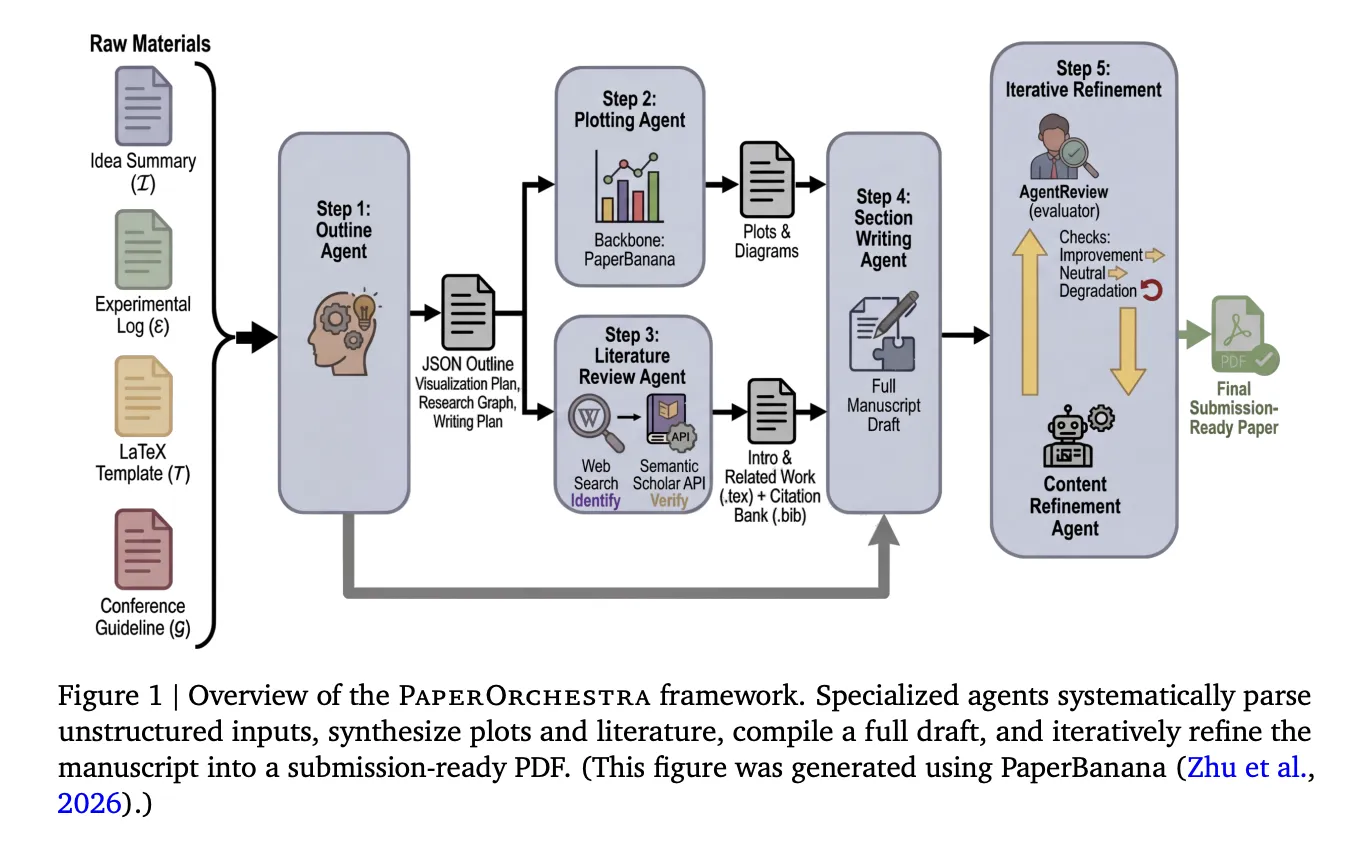
How the pipeline works
PaperOrchestra coordinates 5 specialised brokers that function in sequence and two that run in parallel.
Step 1 — Define Agent: This agent reads the thought define, experiment log, LaTeX assembly template, and assembly pointers and generates a structured JSON define. This overview features a visualization plan (specifying what plots and figures to generate), a focused literature search technique that separates the macro-level context of the Introduction from micro-level methodological clusters of associated research, and a section-level writing plan that features quotation hints for all datasets, optimizers, metrics, and baseline strategies talked about within the materials.
Steps 2 and three — Plot Agent and Literature Overview Agent (in parallel): The Plot Agent executes the visualization plan utilizing PaperBanana, an educational illustration software that makes use of a Visible Language Mannequin (VLM) critic to judge and iteratively modify the generated pictures in opposition to the design objectives. On the identical time, the literature assessment agent runs a two-phase quotation pipeline. We use LLM with internet search to determine candidate papers, then validate every paper by means of the Semantic Scholar API, examine for legitimate fuzzy title matches utilizing Levenshtein distance, retrieve abstracts and metadata, and implement short-term deadlines tied to convention submission deadlines. Illusions and unverifiable references are discarded. Verified citations are compiled into BibTeX information, and brokers use them to draft the Introduction and Associated Works sections. Nevertheless, there’s a strict constraint that at the very least 90% of the collected literature pool have to be actively cited.
Step 4 — Part Creation Agent: This agent takes the whole lot that has been generated to date (Abstract, verified citations, generated figures) and creates the remaining sections (Summary, Methodology, Experiments, Conclusions). Construct tables by extracting numbers straight from experiment logs and combine the generated figures into your LaTeX supply.
Step 5 — Content material Refinement Agent: This agent iteratively optimizes your manuscript utilizing AgentReview, a simulated peer assessment system. After every revision, a manuscript will solely be accepted if the general AgentReview rating will increase or matches a web non-negative sub-axis achieve. In case your total rating drops, it’s going to immediately change again and cease. Ablation outcomes exhibit that this step is vital. Refined manuscripts outperformed unrefined drafts with a win charge of 79% to 81% in automated side-by-side comparisons, and achieved absolute go charge enhancements of +19% in CVPR and +22% in ICLR in AgentReview simulations.
The whole pipeline executes roughly 60-70 LLM API calls and takes a mean of 39.6 minutes per paper to finish. That is solely about 4.5 minutes longer than AI Scientist-v2’s 35.1 minutes, although the variety of LLM calls carried out was considerably greater (40-45 for AI Scientist-v2 and 60-70 for PaperOrchestra).
Benchmark: PaperWritingBench
The analysis crew additionally introduces PaperWritingBench, which is alleged to be the primary standardized benchmark particularly for AI analysis paper writing. It contains 200 accepted papers at CVPR 2025 and ICLR 2025 (100 from every venue), chosen to check adaptation to completely different convention codecs (two-column for CVPR and one-column for ICLR).
For every paper, LLM was used to reverse engineer two inputs from the printed PDF: a sparse thought abstract (rationalization of superior ideas, no arithmetic or LaTeX) and a dense thought abstract (containing formal definitions, loss features, and LaTeX equations). Along with this, an experiment log was additionally created which was obtained by extracting all numerical knowledge and changing graphical insights into unbiased factual observations. All supplies had been totally anonymized and creator names, titles, citations, and determine references had been eliminated.
This design separates the writing activity from the precise experimentation pipeline and makes use of precise accepted papers as floor fact. This reveals one thing vital. For total paper high quality, dense thought settings are considerably higher than sparse thought settings (43%-56% vs. 18%-24% win charge), as a extra exact methodological description permits for extra rigorous part creation. Nevertheless, for the standard of the literature assessment, the 2 settings are nearly the identical (sparse: 32% to 40%, dense: 28% to 39%). Which means that literature assessment brokers can autonomously determine analysis gaps and related citations with out counting on enter from detail-oriented individuals.
consequence
In automated parallel (SxS) evaluations utilizing each Gemini-3.1-Professional and GPT-5 as assessment fashions, PaperOrchestra dominated in literature assessment high quality, attaining an absolute win charge of 88% to 99% in opposition to the AI baseline. By way of total paper high quality, it outperformed AI Scientist-v2 by 39% to 86% and single agent by 52% to 88% throughout all settings.
Human analysis was carried out by 11 AI researchers throughout 180 paired manuscript comparisons, confirming the automated outcomes. PaperOrchestra achieved an absolute win margin of fifty% to 68% over the AI baseline in literature assessment high quality and 14% to 38% in total manuscript high quality. As well as, we achieved a tie win charge of 43% in opposition to human-written floor fact in doc synthesis. It is a outstanding consequence for a completely automated system.
The numbers within the quotation vary inform a very clear story. Within the AI baseline, the common variety of citations per paper was solely 9.75 to 14.18, inflating the F1 rating for the “Quotation Required” (P0) reference class, whereas the recall for “Quotation Eligible” (P1) remained close to zero. PaperOrchestra generated a mean of 45.73 to 47.98 citations, carefully mirroring the roughly 59 citations present in human-written papers, and improved P1 Recall by 12.59% to 13.75% in comparison with the strongest baseline.
Below ScholarPeer’s analysis framework, PaperOrchestra achieved simulated go charges of 84% for CVPR and 81% for ICLR, in comparison with human-generated floor fact charges of 86% and 94%, respectively. This outperformed the strongest autonomous baseline with an absolute acceptance achieve of 13% in CVPR and 9% in ICLR.
Particularly, even when PaperOrchestra autonomously generates its personal diagrams from scratch (PlotOn mode) relatively than utilizing human-authored diagrams (PlotOff mode), it nonetheless achieves ties or wins in 51% to 66% of parallel matches, as human-authored diagrams are sometimes embedded with supplementary outcomes not current within the uncooked experiment log, regardless of the inherent informational benefit of PlotOff.
Necessary factors
This isn’t a analysis bot, however a standalone author. PaperOrchestra is particularly designed to will let you work with supplies corresponding to tough thought outlines and uncooked experiment logs with out having to carry out the experiment itself. It is a direct repair for the largest limitation of present methods like AI Scientist-v2, which solely write papers as a part of their very own inner analysis loops. The standard of citations, not simply the variety of citations, is the true differentiator. This appears acceptable till you notice that competing methods common 9 to 14 citations per paper, that are nearly totally apparent “should cite” references. PaperOrchestra recorded a mean of 45 to 48 citations per paper, per human-authored papers (roughly 59), and dramatically improved protection of “citation-friendly” bibliographies that point out a broader scholarly context, i.e. true scholarly depth. Multi-agent specialization at all times outperforms single-agent prompting. Single-agent baselines (one monolithic LLM name with all the identical uncooked supplies) outperformed PaperOrchestra by 52% to 88% in total paper high quality. The framework’s 5 specialised brokers, parallel execution, and iterative refinement loops carry out work that can not be duplicated with a single immediate, no matter high quality. Content material Refinement Agent will not be non-obligatory. On account of the ablation, we discovered that eradicating the peer assessment repeat loop considerably degraded the standard. In side-by-side comparisons, polished manuscripts outperformed unpolished manuscripts 79% to 81% of the time, with simulated acceptance charges rising by +19% for CVPR and +22% for ICLR. This step alone will get you to a useful draft prepared for submission. Human researchers nonetheless preserve updated, they usually want to take action. The system can not explicitly fabricate new experiment outcomes, and its refinement brokers are instructed to disregard reviewer requests for knowledge not current within the experiment log. The authors place PaperOrchestra as a sophisticated assist software, with human researchers taking full accountability for the accuracy, originality, and validity of the ultimate manuscript.
Take a look at our papers and tasks web page. Additionally, be at liberty to comply with us on Twitter. Additionally, do not forget to hitch the 120,000+ ML SubReddit and subscribe to our e-newsletter. hold on! Are you on telegram? Now you can additionally take part by telegram.
Must companion with us to advertise your GitHub repository, Hug Face Web page, product releases, webinars, and extra? Join with us


