



Most agent frameworks nonetheless run a predefined Motive, Act, Observe loop, so brokers can solely use instruments inserted on the immediate. This works for small duties, however fails when the toolset is giant, when the duty is lengthy, and when the agent wants to alter technique halfway by inference. Renmin College of China and Xiao Hongshu’s crew suggest DeepAgent as an end-to-end deep inference agent that retains all of this inside one coherent inference course of.
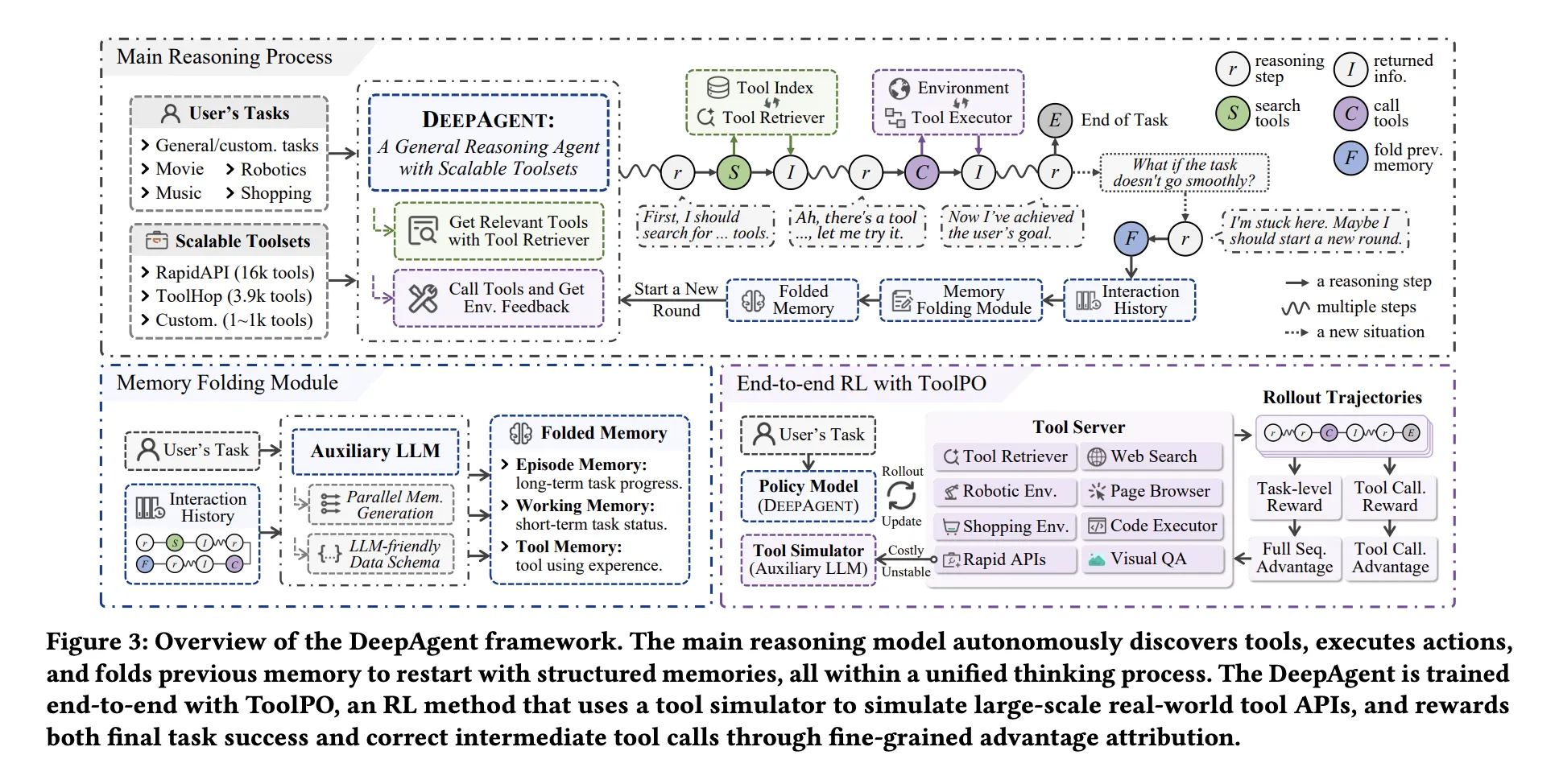
Built-in inference with on-demand software discovery
DeepAgent permits fashions to output 4 motion varieties instantly in textual content: inside ideas, software searches, software calls, and reminiscence folds. When the agent decides to go looking, it queries a dense index containing software descriptions from a big registry (for instance, over 16,000 RapidAPI instruments and three,912 ToolHop instruments) and receives solely the top-ranked instruments inside its context. This makes entry to instruments dynamic, the mannequin doesn’t depend on a frontloaded software listing, and it stays in line with the true world the place instruments change.
Autonomous reminiscence folding for long-running duties.
Lengthy sequences of software calls, net outcomes, and code responses overflow the context. DeepAgent solves this with an autonomous reminiscence folding step. When the mannequin points a fold token, the auxiliary LLM compresses the whole historical past into three recollections: episodic reminiscence that data activity occasions, working reminiscence that data present subgoals and up to date issues, and power reminiscence that data software names, arguments, and outcomes. These recollections are fed again as structured textual content, so the agent continues from a compact however information-rich state.
ToolPO, reinforcement studying for software utilization
Supervised tracing can’t educate you how one can use a software reliably, since an accurate software name is only some tokens in an extended era. The analysis crew launched the software Coverage Optimization (ToolPO) to resolve this drawback. As a result of ToolPO performs rollouts on LLM-simulated APIs, coaching is steady and low-cost, and rewards are attributed to correct software name tokens. It is a software name profit attribution and is educated utilizing clipped PPO fashion aims. This teaches the agent not solely how one can name instruments, but in addition how one can resolve when to go looking and when to fold reminiscence.
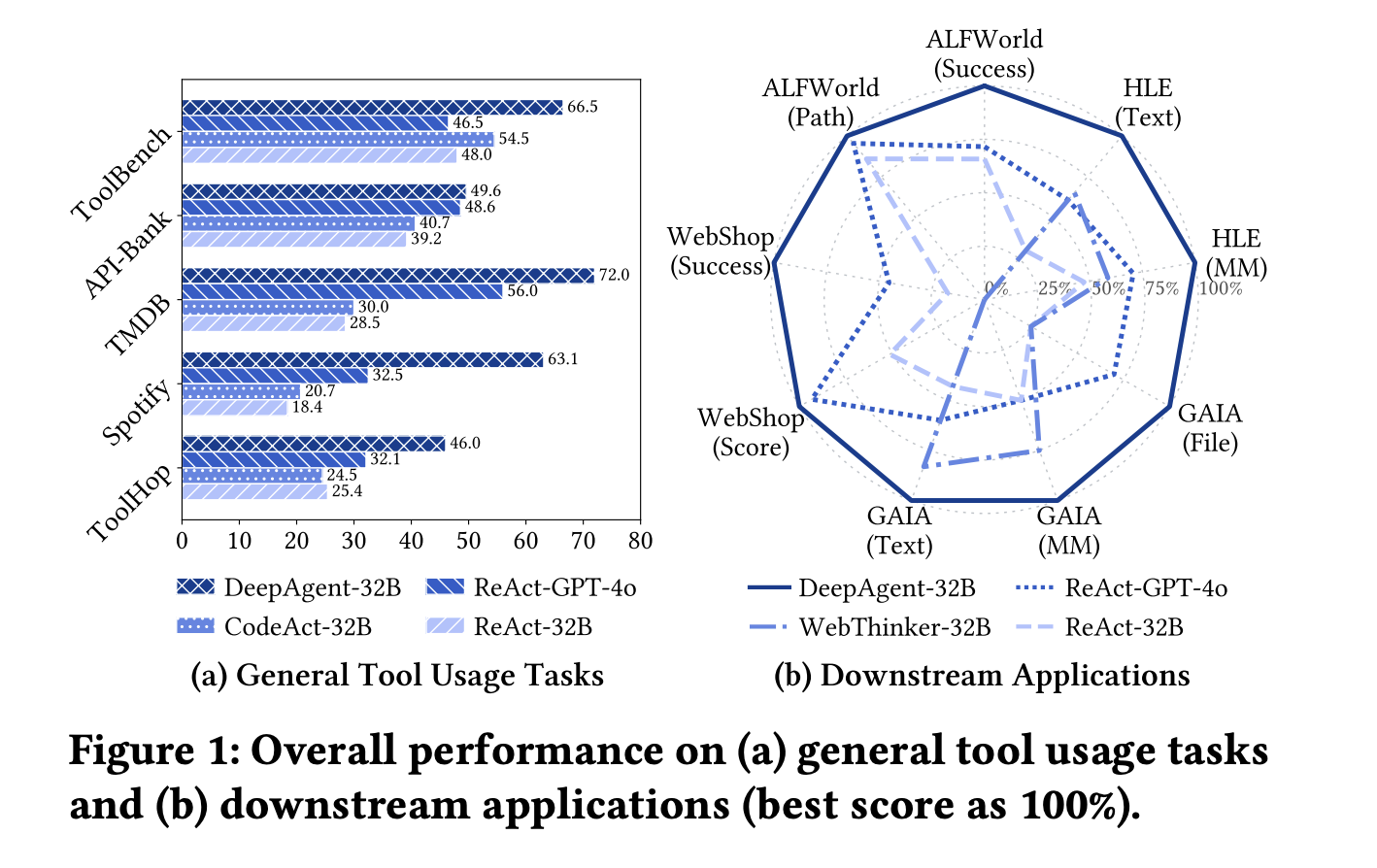
Benchmarking, evaluating labeled and open set instruments
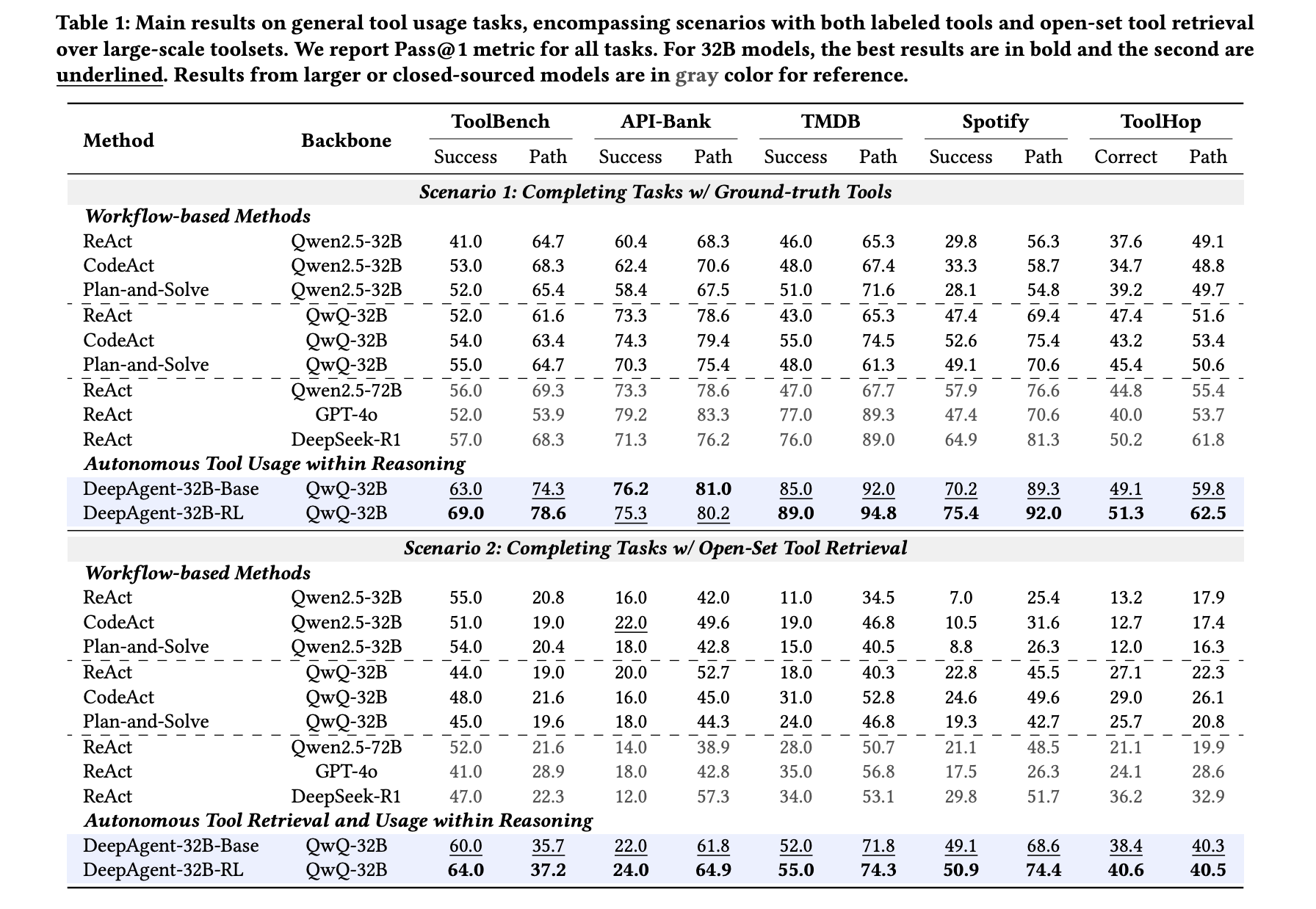
The analysis crew evaluates 5 widespread software utilization benchmarks: ToolBench, API Financial institution, TMDB, Spotify, and ToolHop, and 4 downstream duties: ALFWorld, WebShop, GAIA, and HLE. Within the labeled software configuration, the place all strategies are given the precise instruments wanted, a DeepAgent 32B RL with a QwQ 32B spine stories 69.0 on ToolBench, 75.3 on API Financial institution, 89.0 on TMDB, 75.4 on Spotify, and 51.3 on ToolHop. That is the strongest 32B degree end result throughout all 5 datasets. Workflow baselines akin to ReAct and CodeAct match a single dataset. For instance, ReAct with a powerful mannequin reveals excessive values on TMDB and Spotify, however none maintains excessive values on all 5. So, a good abstract is that DeepAgent is extra uniform and different datasets aren’t at all times decrease.
In a sensible configuration, an open set acquisition configuration, DeepAgent should first find the software after which name it. Right here, the DeepAgent 32B RL reaches 64.0 on ToolBench and 40.6 on ToolHop, however the end-to-end agent nonetheless holds the lead as essentially the most highly effective workflow baseline reaches 55.0 on ToolBench and 36.2 on ToolHop. The researchers additionally present that whereas autonomous software acquisition itself improves workflow brokers, DeepAgent goes past that, confirming that the structure and coaching are well-suited for giant toolsets.
downstream setting
On ALFWorld, WebShop, GAIA, and HLE, all below the 32B inference mannequin, DeepAgent reported 91.8 p.c success on ALFWorld, 34.4 p.c success on WebShop, and a rating of 56.3, and 53.3 on GAIA, scoring increased than the workflow agent on HLE. These duties are lengthy and noisy, so a mix of reminiscence folding and ToolPO could also be the reason for the hole.
Vital factors
DeepAgent retains the complete agent loop inside one inference stream, permitting the mannequin to suppose, seek for instruments, invoke, and proceed, so you are not restricted to a hard and fast ReAct-style workflow. Utilizing a big software registry, high-density seek for over 16,000 RapidAPI instruments, and roughly 3,900 ToolHop instruments, instruments are found on-demand fairly than having to be pre-listed in a immediate. Autonomous reminiscence folding modules compress lengthy interplay histories into episodic, working, and power recollections. This prevents context overflow and maintains inference stability over time. Device Coverage Optimization (ToolPO) trains end-to-end utilization of instruments utilizing simulated APIs and token-level profit attribution. So the agent not solely arrives on the remaining reply, but in addition learns how one can challenge the right software calls. Throughout 5 software benchmarks and 4 downstream duties, DeepAgent at 32B scale is extra constant than the workflow baseline in each labeled and open set settings, particularly ToolBench and ToolHop, the place software discovery is most necessary.
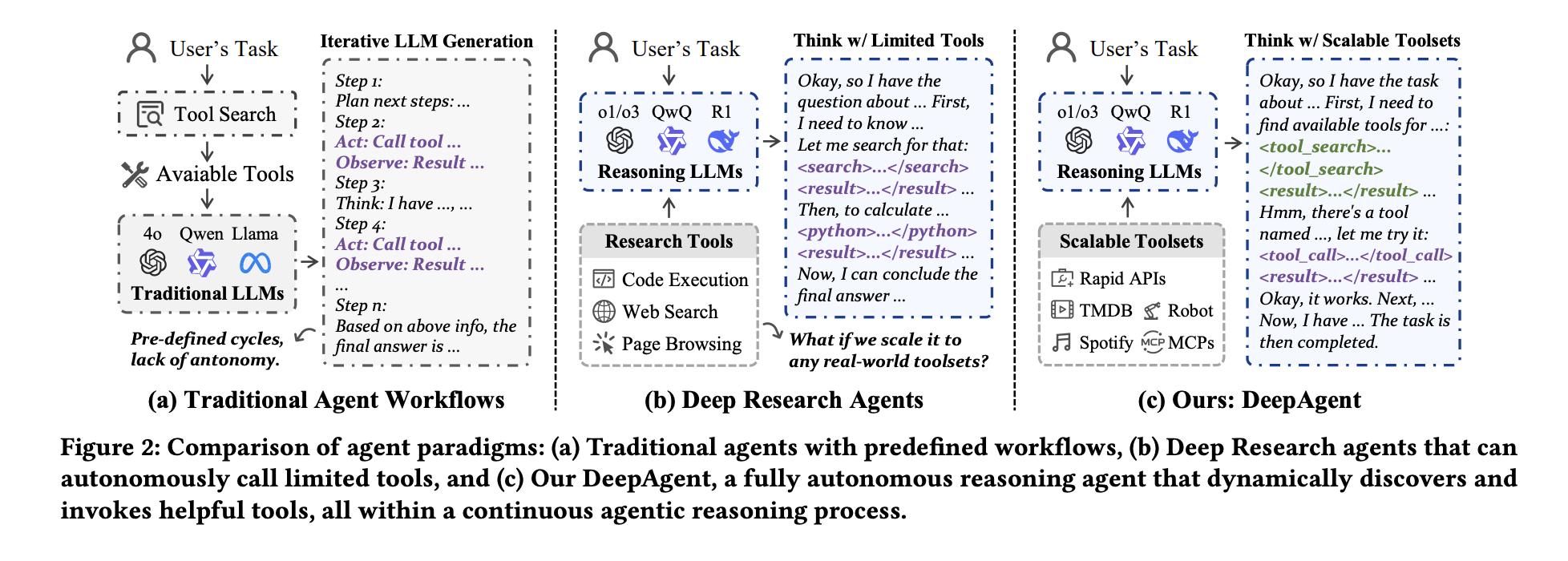
DeepAgent integrates autonomous pondering, dense software retrieval over 16,000 RapidAPI and three,900 ToolHop instruments, structured software invocation, and reminiscence folding into one loop, making it a sensible step towards agent architectures that do not depend on mounted software prompts. Utilizing the LLM Simulate API in ToolPO is an engineering selection, but it surely solves the latency and instability points that plagued earlier software brokers. Analysis reveals constant 32B degree positive factors with no remoted peaks for each labeled instruments and open-set settings. This launch permits the LLM agent to make use of a very giant toolspace. General, DeepAgent sees end-to-end tooling brokers with reminiscence and RL rising because the default sample.
Try our Paper and GitHub repositories. Be happy to go to our GitHub web page for tutorials, code, and notebooks. Additionally, be at liberty to observe us on Twitter. Additionally, do not forget to affix the 100,000+ ML SubReddit and subscribe to our e-newsletter. grasp on! Are you on telegram? Now you can additionally take part by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a man-made intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views per 30 days, demonstrating its recognition amongst viewers.
🙌 Observe MARKTECHPOST: Add us as your most well-liked supply on Google.


