



TL;DR
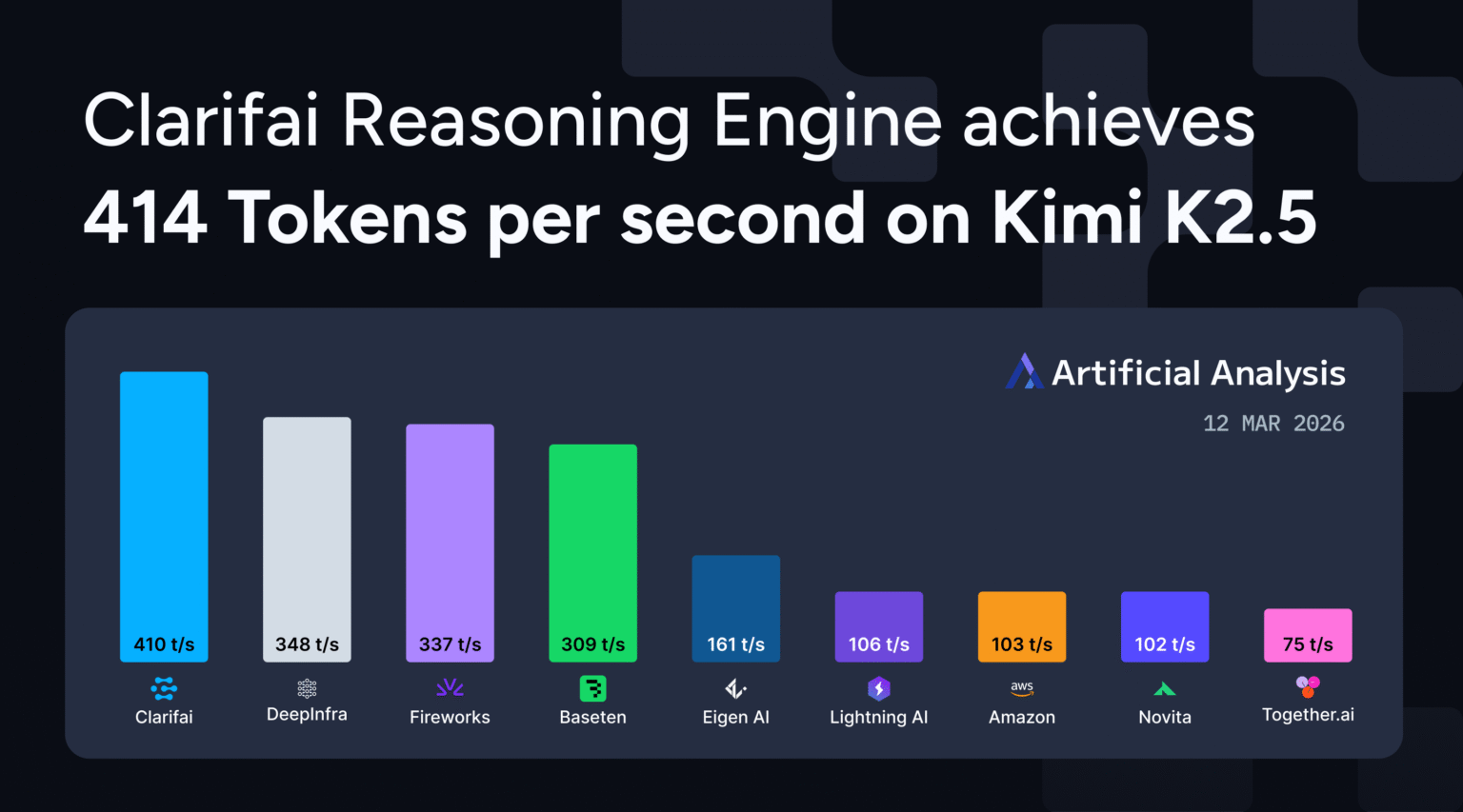
Through the use of a customized CUDA kernel and speculative decoding optimized for inference workloads, we achieved a throughput of 414 tokens per second on Kim K2.5 operating on an Nvidia B200 GPU. This makes us one of many first suppliers to succeed in over 400 tokens per second with a 1 trillion parameter inference mannequin.
We’re excited to share it forward of Nvidia GTC Clarifai inference engine Kimi achieved a throughput of 414 tokens per second (TPS) with K2.5, rating it among the many prime inference suppliers for Frontier inference fashions. synthetic evaluation. Our platform, operating on Nvidia B200 GPU infrastructure, offers production-grade efficiency for agent workflows and complicated inference duties.
Determine 1: Clarifai achieves 414 tokens per second on Kim K2.5, rating as one of many quickest inference suppliers within the Synthetic Evaluation benchmark.
Why your K2.5’s efficiency issues
Kimi K2.5 is a trillion-parameter inference mannequin with a 384-expert mixed-expert structure that prompts 32 billion parameters per request. Constructed by Moonshot AI with native multimodal coaching on 15 trillion combined visible and textual tokens, the mannequin delivers robust efficiency throughout key benchmarks. HLE utilizing the instrument was 50.2%, SWE-Bench validated was 76.8%, and BrowseComp was 78.4%.
As a reasoning mannequin, Kimi K2.5 generates an prolonged thought sequence earlier than the ultimate reply. Clarifai achieved a time to first response token of 6 seconds. This contains the mannequin’s inner suppose time earlier than offering a response. Throughput straight impacts the end-to-end response time of agent programs, code technology, and multimodal inference duties. 414 TPS to get the velocity you want for manufacturing deployments.

Determine 2: Time to first response token (TTFT) efficiency throughout inference suppliers as measured by synthetic evaluation utilizing 10,000 enter tokens.
Tips on how to optimize throughput
Clarifai inference engine Use three core optimizations for large-scale inference fashions.
Customized CUDA kernel Reduces reminiscence stalls and enhances cache locality. Optimize low-level GPU operations to maintain streaming multiprocessors lively throughout inference, somewhat than ready for knowledge to maneuver.
speculative decoding Predict attainable token paths and remove errors rapidly. This reduces wasted computation through the mannequin’s thought sequence, a standard sample in inference workloads.
adaptive optimization Constantly be taught from workload conduct. The system dynamically adjusts batch processing, reminiscence reuse, and execution paths based mostly on precise request patterns. These enhancements worsen over time, particularly for repetitive duties widespread in agent workflows.
Operating on the Nvidia B200 infrastructure provides you the {hardware} basis to push the boundaries of efficiency, whereas the inference optimization stack delivers software-level enhancements.
Create with you K2.5
Kimi K2.5 is now accessible on the Clarifai platform. Strive it out first through the Playground or API.
If you happen to want devoted compute to deploy Kimi K2.5 or different related prime open fashions at scale for manufacturing workloads, contact our workforce.


