




Every time you immediate LLM, it constructs the response one phrase (or token) at a time, relatively than producing the entire response suddenly. At every step, the mannequin predicts what the following token is prone to be primarily based on all the things written to this point. However simply figuring out the possibilities will not be sufficient. The mannequin additionally requires a method to really determine which token to decide on subsequent.
Totally different methods can utterly change the look of the ultimate output. Some methods will be extra targeted and exact, whereas others will be extra inventive or numerous. This text opinions 4 widespread textual content era methods utilized in LLM: grasping search, beam search, nuclear sampling, and temperature sampling, and explains how every works.
grasping search
Grasping Search is the best decoding technique the place at every step the mannequin selects the token with the best chance contemplating the present context. Though it’s fast and simple to implement, it doesn’t all the time produce essentially the most constant and significant sequences. That is much like making domestically optimum selections with out contemplating the worldwide consequence. As a result of it follows just one path within the chance tree, it could miss higher sequences that require short-term trade-offs. In consequence, grasping searches typically produce repetitive, generic, or boring textual content, making them unsuitable for open-ended textual content era duties.
beam search
Beam search is an improved decoding technique over grasping search that tracks a number of doable sequences (known as beams) as an alternative of only one at every era step. This expands the highest Okay almost definitely sequences and permits the mannequin to discover a number of promising paths within the chance tree, doubtlessly discovering greater high quality completions {that a} grasping search would possibly miss. The parameter Okay (beam width) controls the trade-off between high quality and computation. A bigger beam will produce higher textual content, however will likely be slower.
Whereas beam search works properly for structured duties like machine translation, the place accuracy is extra necessary than creativity, open-ended era tends to supply textual content that’s repetitive, predictable, and lacks selection. This occurs as a result of the algorithm prioritizes continuations with excessive possibilities, leading to fewer variations, leading to “neural textual content degeneration” the place the mannequin overuses sure phrases and phrases.
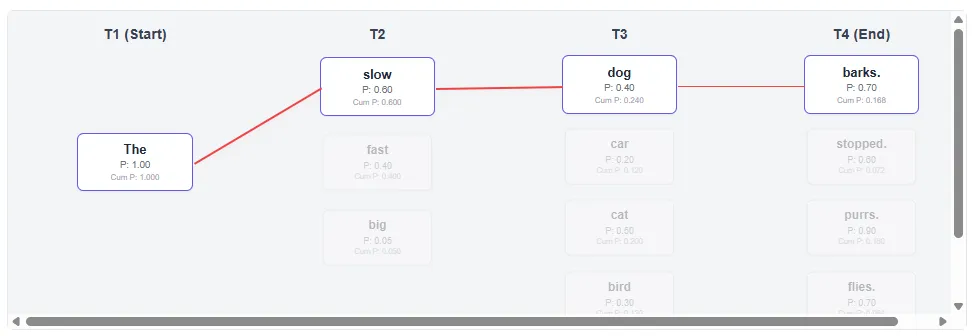
Grasping search:
Beam search:
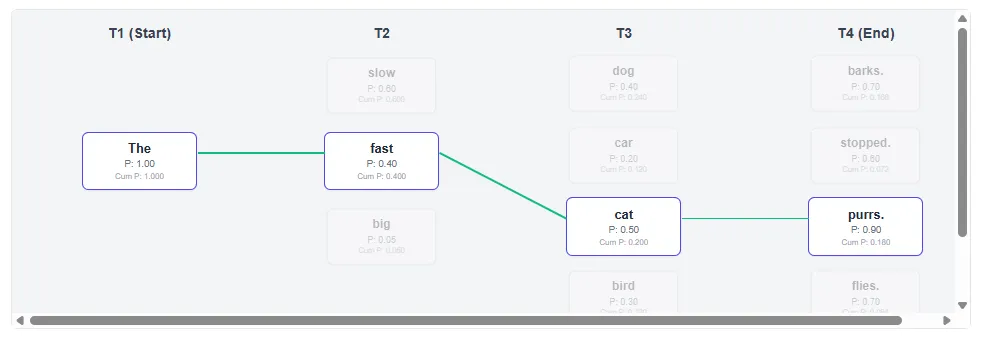
Grasping search (Okay=1) all the time takes the best native chance. T2: Choose “Gradual” (0.6) as an alternative of “Quick” (0.4). Ensuing path: “Gradual canine barks.” (Closing chance: 0.1680) Beam search (Okay=2) preserves each “gradual” and “quick” paths. In T3, we see that paths that begin with “quick” usually tend to have ending. Consequence path: “A quick cat purrs.” (Closing chance: 0.1800)
Beam Search efficiently explored barely decrease chance paths early on, bettering general sentence scores.
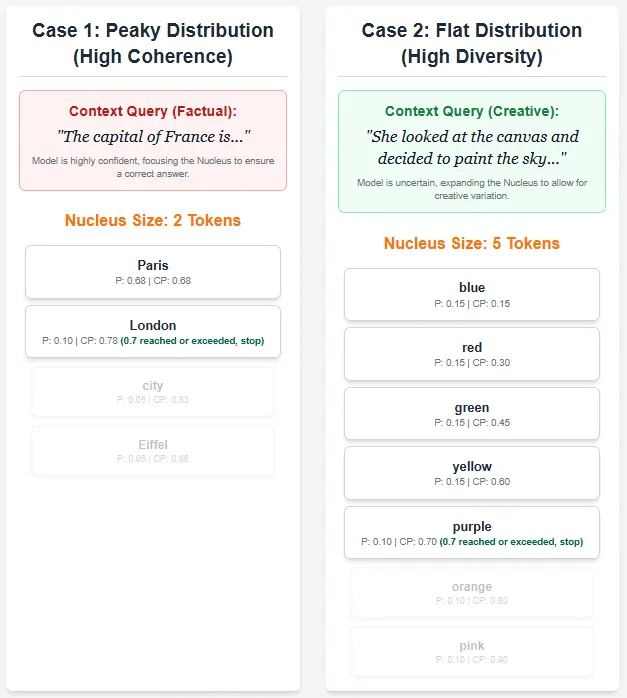
High-p sampling (Nucleus sampling) is a probabilistic decoding technique that dynamically adjusts the variety of tokens thought-about for era at every step. Moderately than choosing from a hard and fast variety of high tokens as in top-k sampling, top-p sampling selects the smallest set of tokens whose cumulative possibilities sum to a particular threshold p (for instance, 0.7). These tokens type a “nucleus” from which the following token is randomly sampled after normalizing the possibilities.
This permits the mannequin to stability variety and consistency. This implies you may pattern from a wider vary if many tokens have comparable possibilities (flat distribution), and slim all the way down to the almost definitely tokens if the distribution is sharp (peaky). In consequence, top-p sampling produces extra pure, numerous, and context-appropriate textual content in comparison with fixed-size strategies comparable to grasping search and beam search.
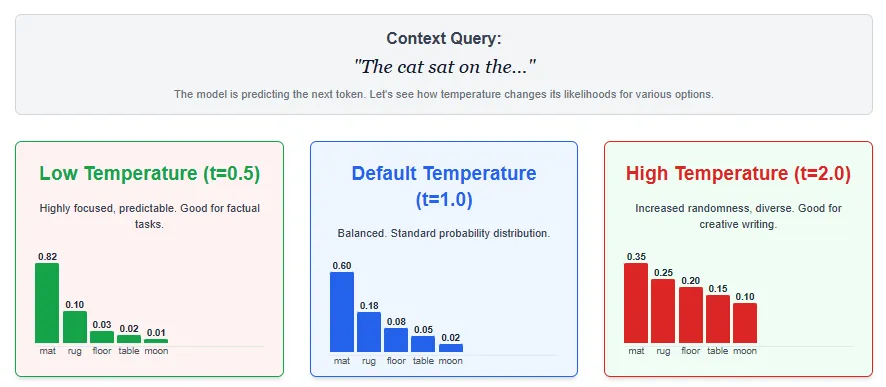
temperature sampling
Temperature sampling controls the extent of randomness in textual content era by adjusting the temperature parameter
Larger temperatures (t > 1) flatten the distribution, introducing extra randomness and variety, however at the price of consistency. In reality, temperature sampling lets you fine-tune the stability between creativity and precision. Decrease temperatures produce extra definitive and predictable output, whereas greater temperatures produce extra different and imaginative textual content.
The optimum temperature typically depends upon the duty. For instance, inventive writing could profit from greater values, whereas technical or factual responses could carry out higher with decrease values.

I’m a Civil Engineering graduate from Jamia Millia Islamia, New Delhi (2022) and have a powerful curiosity in knowledge science, particularly neural networks and their functions in numerous fields.
🙌 Observe MARKTECHPOST: Add us as your most popular supply on Google.


