




A mild introduction to batch normalization
Photos by editor | chatgpt
introduction
Deep neural networks have advanced considerably over time and overcome the widespread challenges that come up when coaching these advanced fashions. This evolution has enabled them to successfully remedy more and more troublesome issues.
One mechanism that has a specific impression on the developments in neural network-based fashions is batch normalization. This text supplies a delicate introduction to this technique. This has turn into the usual for a lot of fashionable architectures and helps to enhance mannequin efficiency by stabilizing coaching and dashing up convergence.
How and why did batch normalization come about?
Batch normalization was about 10 years in the past. Initially proposed by Ioffe and Szegedy in normalising paper batches. Speed up deep community coaching by lowering inner covariate shifts.
Its creation motivation comes from a number of challenges, together with the gradual coaching course of and the saturation points such because the gradient of explosions and disappearance. One explicit problem highlighted within the unique paper is inner covariate shifts. In easy phrases, this downside pertains to how the distribution of inputs to every layer of neurons continues to vary throughout coaching. These distribution shifts could cause some sort of “rooster and egg” issues as they pressure the community to proceed to be readjusted, resulting in unfair and unstable coaching.
How does it work?
In response to the aforementioned issues, batch normalization was proposed as a technique of normalizing inputs to layers inside neural networks, which helped to stabilize the coaching course of ongoing.
In observe, batch normalization entails introducing an extra normalization step earlier than the assigned activation perform is utilized to the weighted enter of such a layer, as proven within the diagram under.
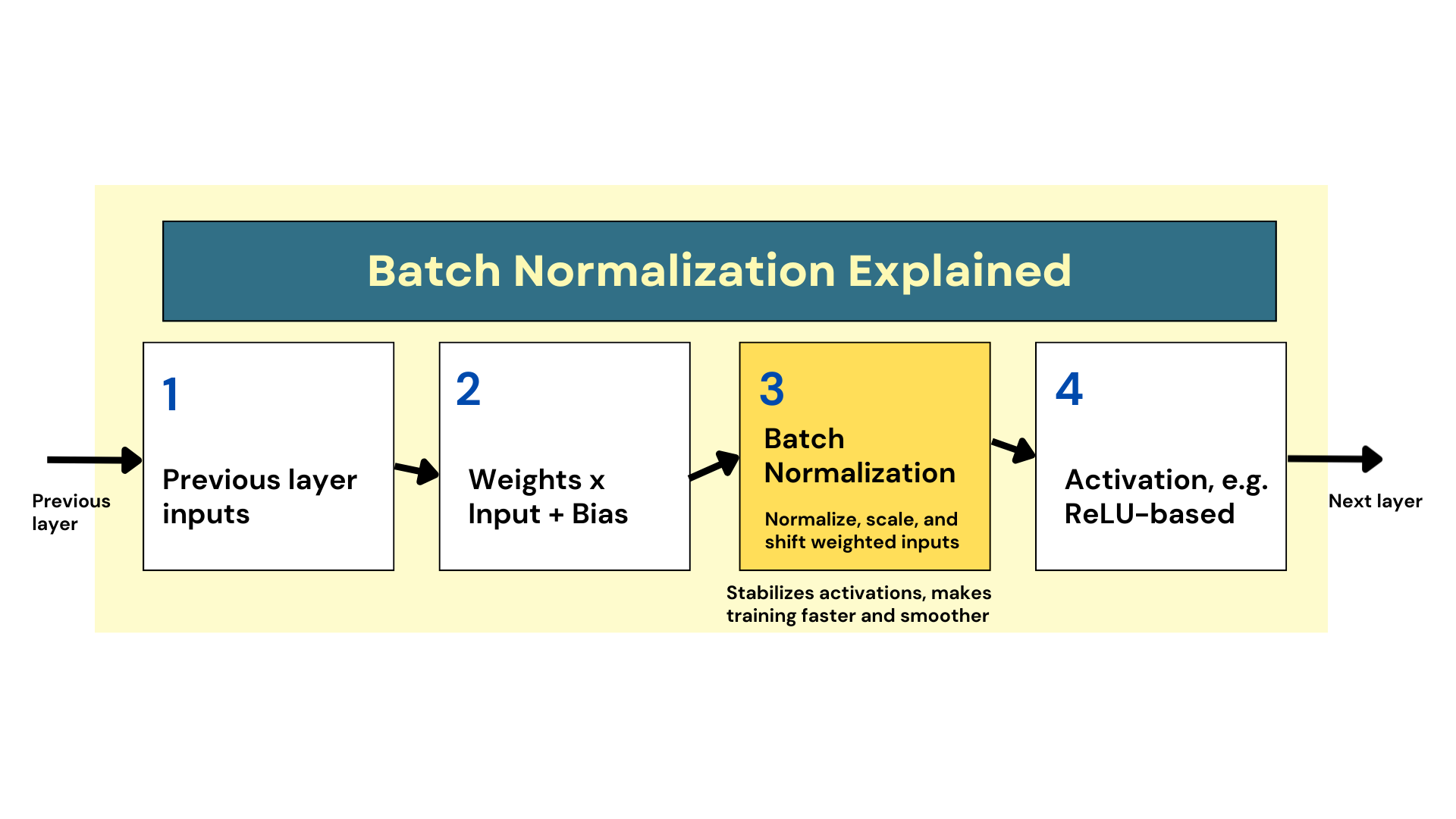
How batch normalization works
Photos by the creator
In its easiest type, the mechanism consists of zero facilities, scaling, and enter shifts, guaranteeing that the values stay inside a extra constant vary. This easy thought will assist the mannequin be taught the optimum scale and be taught the common enter on the layer degree. Consequently, the gradient flowing backwards to replace weight throughout backpropagation does so extra easily, lowering negative effects resembling weight initialization strategies, resembling HE initialization. And most significantly, this mechanism has been confirmed to advertise sooner and extra dependable coaching.
At this level, two typical questions might come up:
Why is the “batch” in batch normalization? :If you’re fairly acquainted with the fundamentals of coaching neural networks, you’ll discover that the coaching set is normally divided into mini-batches containing 32 or 64 situations, dashing up and scaling the optimization course of underlying the coaching. Subsequently, the method is as a result of the imply and variance used to normalize the weighted enter is calculated on the batch degree fairly than on the whole coaching set. Can or not it’s utilized to all layers in a neural community? :Batch normalization is normally utilized to hidden layers the place activation can turn into unstable throughout coaching. It’s uncommon to use batch normalization to the enter layer, as uncooked inputs are normally pre-normalized. Equally, making use of it to the output layer is counterproductive. Specifically, for regression neural networks to foretell elements resembling flight value, rainfall, and many others., it might break assumptions made for the anticipated vary of output values.
A significant constructive impact of batch normalization is a major discount within the disappearing gradient downside. It additionally supplies extra robustness, reduces sensitivity to chose weight initialization strategies and introduces normalization results. This regularization may also help fight over-deadlines and will remove the necessity for different particular methods, resembling dropouts.
Learn how to implement it in Keras
Keras is a well-liked Python API along with Tensorflow, which is used to construct neural community fashions. This is a crucial step earlier than coaching when designing the structure. This instance exhibits how simple it’s to implement batch normalization on a easy neural community to coach on Keras.
Import sequentials from tensorflow.keras.fashions from tensorflow.keras.layers.[
Dense(64, input_shape=(20,)),
BatchNormalization(),
Activation(‘relu’),
Dense(32),
BatchNormalization(),
Activation(‘relu’),
Dense(1, activation=’sigmoid’)
])mannequin.compile(optimizer=adam(), loss=”binary_crossentropy”, metrics=[‘accuracy’])mannequin.abstract()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
twenty one
from Tensorflow.Keras.Mannequin Import A collection
from Tensorflow.Keras.Layer Import Shut-up, Batch normalization, Activation
from Tensorflow.Keras.Optimizer Import Adam
Mannequin = A collection([
Dense(64, input_shape=(20,)),
BatchNormalization(),
Activation(‘relu’),
Dense(32),
BatchNormalization(),
Activation(‘relu’),
Dense(1, activation=‘sigmoid’)
]))
Mannequin.compile(optimizer=Adam()),
loss=“binary_crossentropy”,
metric=[‘accuracy’]))
Mannequin.abstract())
Introduction of this technique is so simple as including batchnormalization() between the layer definition and its related activation perform. The enter layer on this instance will not be explicitly outlined, and the primary focus layer acts as the primary hidden layer that has been efficiently entered.
Importantly, word that by incorporating batch normalization, every subcomponent inside a layer is outlined individually, making it not possible to specify an activation perform as an inner argument within the layer definition (32, activation = ‘lelu’). Nonetheless, conceptually talking, regardless of Keras and Tensorflow internally managing them as separate sublayers, three strains of code will be interpreted as one neural community layer fairly than three.
I am going to summarize
This text supplied a delicate and pleasant introduction to batch normalization. This can be a easy but extremely efficient mechanism that helps to alleviate a few of the widespread issues discovered when coaching neural community fashions. Easy phrases (or at the very least I attempted!), there isn’t a math right here and there. Additionally, since I am just a little extra technically savvy, it is a ultimate (reasonable) instance of learn how to implement it in Python.


